Pour extraire des données de sites Web, vous pouvez profiter d’outils d’extraction de données tel qu’Octoparse. Ces outils peuvent extraire automatiquement les données des sites Web et vous pouvez les enregistrer dans de nombreux formats tels qu’Excel, JSON, CSV, HTML, Google Sheets ou dans votre propre base de données via des APIs. Dans seulement quelques minutes, des milliers de lignes de données serons extraites. Ce qui serait le plus attirant pour vous, c’est qu’aucun codage n’est requis dans ce processus.
Prenons Google Search comme un exemple. Supposons que nous désirons collecter toutes les informations relatives à “web scraping”, y compris titres, descriptions et URLs de pages Web dans les résultats de recherche. Dans cet article, nous allons vous présenter comment extraire automatiquement les données du site Web vers Excel avec Octoparse dans deux méthodes : mode de template et mode avancé.
Méthod #1 : Extraction avec le Mode de Template en quelques clicse
Pour extraire des données de Google Search, vous pouvez utiliser un modèle de web scraping (ce qu’on appelle également “template”). Un modèle est un crawler pré-construit qu’on peut utiliser directement sans d’autres configurations. Jusque maintenant, Octoparse propose des centaines de modèles qui couvrent des domaines variés, allant des sites de commerce électronique tels qu’Amazon et eBay aux canaux de médias sociaux tels que Twitter, en passant par des sites d’annuaire, d’emploi, d’immobilier, Google Maps, etc. L’équipe d’Octoparse continue de développer les modèles qui apporteront le plus de valeur à ses utilisateurs. De plus, s’il y a des besoins particuliers, Octoparse fournit également un service personnalisé.
Maintenant, voyons les étapes.
Étape 1 : Choisissez un modèle de grattage Web
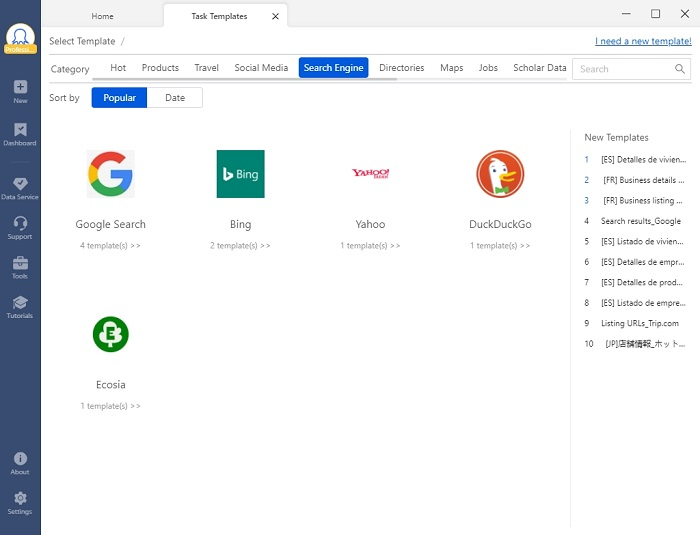
Tout d’abord, vous devez installer Octoparse sur votre ordinateur pour y découvrir les modèles disponibles. Dans notre exemple, il faut aller dans la catégorie “moteur de recherche” et trouver le modèle de Google Search.
Étape 2 : Lisez les instructions du modèle
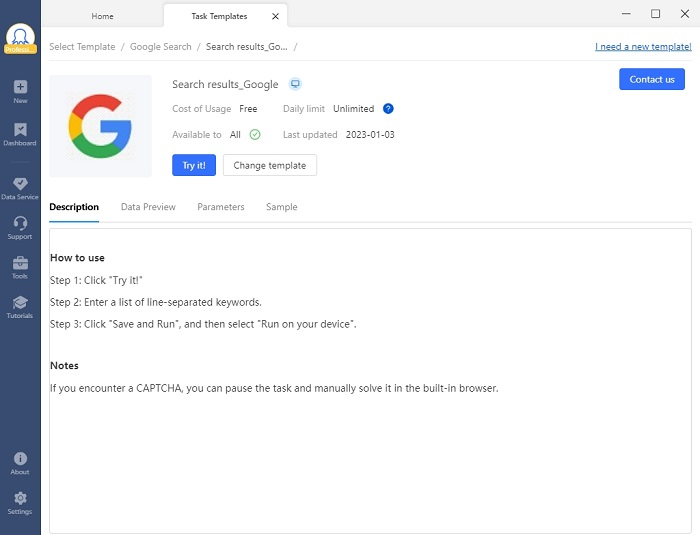
Cliquez sur le modèle et vérifiez l’introduction et la sortie d’exemple pour vous assurer que ce modèle peut extraire les données dont vous avez besoin. Vous pouvez passer le curseur sur le “Data preview” pour voir quels éléments de site Web seront extraits. Il y a une autre partie – “Parameters” – qui est là pour faire savoir ce que vous devez entrer. Les paramètres à entrer varient selon les modèles : URL, mot-clé, nombre de pages à parcourir.
Étape 3 : Utilisez le modèle et lancez l’extraction
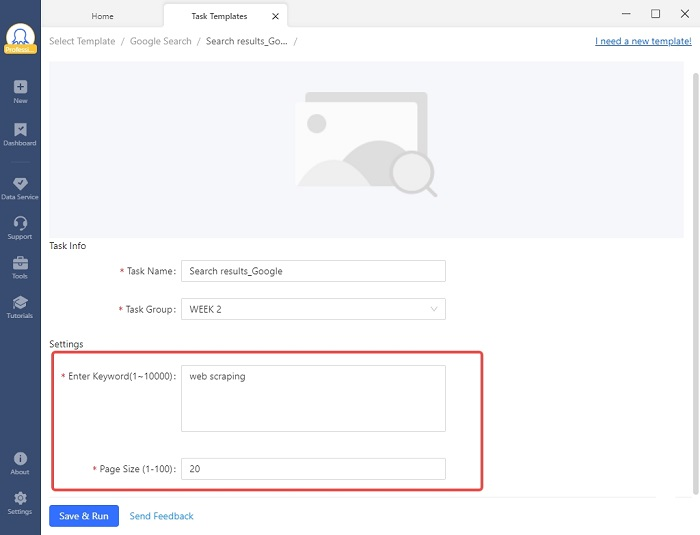
Cliquez sur “Try it” et puis entrez le mot-clé “web scraping” et faire parcourir 20 pages de résultats de recherche par le robot. Après cela, cliquez sur “Save et run” et commencer le scraping. Vous pouvez exécuter le crawler sur votre ordinateur local ou planifier l’extraction sur la plate-forme cloud Octoparse. Quand l’extraction est finie, vous êtes libre à exporter les données dans des formats divers, comme Excel, CSV et txt.
Méthod #2: Extraction de données avec le Mode Avancé
Nous venons de présenter comment utiliser un modèle de scraping pour extraire des données Web de Google Search en quelques clics. Hormis cela, vous pouvez aussi créer facilement votre propre crawler en seulement des clics avec le “Mode avancé” sans aucun codage. Bien que des configurations, cette méthode est très flexible en termes d’extraction de données. Je vous invite à télécharger Octoparse et à suivre ces étapes de près, et vous comprendrez à quel degré l’extraction de données est facile.
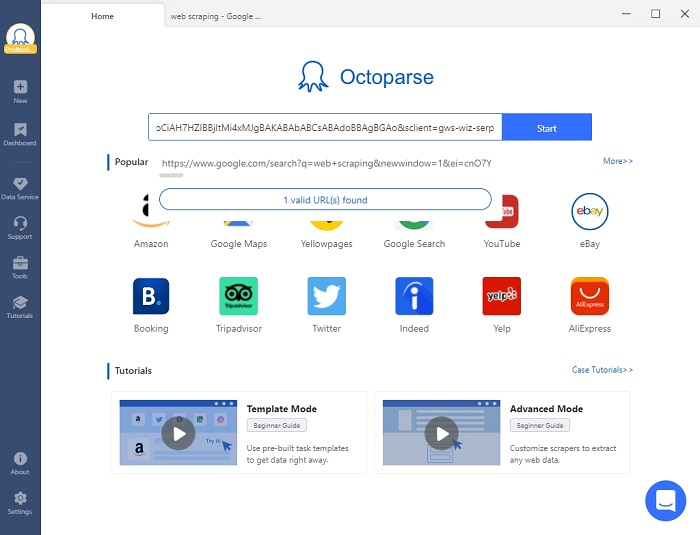
Étape 1 : Saisir l’URL cible pour créer un crawler
Si vous voulez extraire des données à grande échelle, vous pouvez entrer une liste d’ URLs jusqu’à un million de lignes. Dans notre exemple, puisque nous ne voulons scraper qu’un seul site Web, collons simplement l’URL de Google recherche “web scraping” dans la barre de recherche et cliquez sur “Start” pour continuer.
Étape 2 : Créer une boucle de pagination
Octoparse a maintenant chargé la page Web dans son navigateur intégré avec succès. Puisque nous souhaitons scraper les données sur 20 pages, il nous faut créer une boucle de pagination. Les étapes sont assez faciles : cliquez sur le bouton de “Suivant” >> choisissez “Loop click single element” dans le panneau Tips. Et vous pouvez voir la boucle de pagination dans la zone de workflow. Le robot va cliquer automatiquement vers la page suivante après avoir gratté les données sur la page présente.
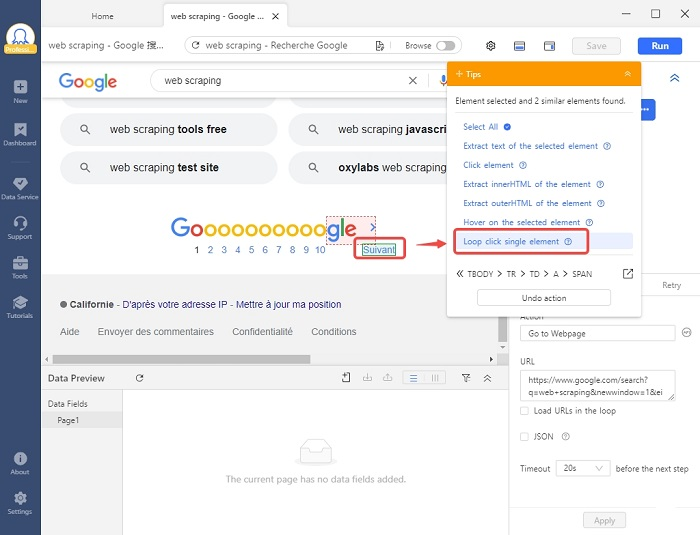
Étape 3 : Sélectionner les données à extraire et lancer l’extraction
Il faut encore indiquer au robot les données dont vous avez besoin.
Cliquez sur le titre d’un résultat de recherche, puis cliquez sur “Select all” dans le panneau de Tips. Les titres seront surlignées en vert. Choisissez “Extract text of the selected elements” pour extraire tous les titres.
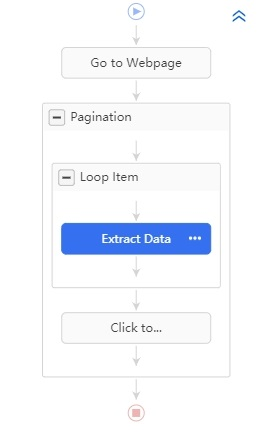
Arrêtez-vous un instant et vérifiez le workflow. Vous venez de construire une boucle d’extraction dans la boucle de pagination avec succès, ce qui veut dire que : le robot ouvrira d’abord la page Web, extraira les titres de la première page un par un, puis entrera dans la page suivante pour répéter l’extraction jusqu’à ce que l’extraction s’arrête ou soit terminée.
Pour extraire les descriptions et les URLs, il suffit de suivre les mêmes étapes. Après avoir sélectionné les données à extraire, vous pouvez modifier le nom des champs, et lancer l’extraction comme vous les ouhaitez.
En plus de Google, les outils de web scraping peuvent aussi extraire des données de nombreux autres sites Web et être largement utilisés dans divers secteurs. Par exemple, une entreprise peut extraire les pages jaunes, Yelp et Google Maps pour générer leurs prospects. En fin de compte, Octoparse est un outil d’extraction de données, et vous pouvez l’utiliser pour obtenir ce dont vous avez besoin.




