Pour scraper un site web sans coder, il faut d’abord choisir le bon outil. Le scraping de site est aujourd’hui une composante stratégique dans de nombreux secteurs : veille concurrentielle, génération de leads, analyse de marché, recherche académique. Que vous soyez débutant ou développeur, il existe un outil adapté à votre niveau, certains entièrement gratuits sans limite de temps, d’autres accessibles sans une seule ligne de code. Ce guide compare les 17 meilleurs web scrapers gratuits en 2026 : pour chaque outil, vous trouverez ses points forts, son niveau technique requis et sa compatibilité, pour choisir rapidement celui qui correspond à votre cas d’usage.

Exportez vos données vers Excel, CSV ou Google Sheets sans écrire une ligne de code.
L’IA détecte automatiquement les données à extraire : aucun XPath ni sélecteur CSS à configurer.
200+ modèles de scraping gratuits prêts à l’emploi pour Amazon, Google Maps, LinkedIn et plus.
Ne soyez jamais bloqué : rotation de proxies IP et contournement des protections anti-scraping intégrés.
Version gratuite sans limite de temps, sans carte bancaire requise.
Comparatif rapide des outils de scraping en 2026
Avant d’entrer dans le détail de chaque outil, voici un tableau synthétique des principaux scrapers gratuits pour identifier rapidement la solution adaptée à votre profil. Les outils ci-dessous couvrent les cas d’usage les plus courants en France en 2026 : la liste complète et détaillée figure dans les sections suivantes.
| Outil | Gratuit | Sans code | Windows / Mac | Cloud | Limite gratuite | Idéal pour |
|---|---|---|---|---|---|---|
| Octoparse | ✅ Sans limite | ✅ | ✅ / ✅ | ✅ | Aucune limite de temps, fonctions cloud payantes | Tous profils |
| ParseHub | ✅ | ✅ | ✅ / ✅ | ✅ payant | 5 projets actifs, 200 pages par run | Débutants |
| Web Scraper | ✅ Extension | ✅ | Chrome | ✅ payant | Local uniquement, cloud payant | Usage ponctuel |
| Instant Data Scraper | ✅ Complet | ✅ | Chrome | ❌ | Pas de planification ni d’export automatique | Extraction rapide |
| Data Miner | ✅ Limité | ✅ | Chrome / Firefox | ❌ | 500 lignes/scrape en version gratuite | Tableaux & listes |
| Scrapy | ✅ Open source | ❌ | ✅ / ✅ | ❌ | Aucune limite technique, hébergement à prévoir | Développeurs |
| Puppeteer | ✅ Open source | ❌ | ✅ / ✅ | ❌ | Aucune limite technique, hébergement à prévoir | Développeurs JS |
| BeautifulSoup | ✅ Open source | ❌ | ✅ / ✅ | ❌ | Aucune limite technique, hébergement à prévoir | Développeurs Python |
| Bright Data | ❌ Payant | ✅ | Cloud | ✅ | Essai gratuit limité uniquement | Entreprises |
| Dexi.io | ✅ Limité | ❌ | Cloud | ✅ | Données hébergées 2 semaines, puis archivées | Utilisateurs avancés |
Ce tableau se concentre sur les outils les plus utilisés en France en 2026. Pour une analyse approfondie incluant les outils pour développeurs et les solutions web avancées, les sections suivantes détaillent les points forts, les limites réelles et les cas d’usage de chacun.
Comment fonctionne les outils de scraping
Le web scraping est le moyen de collecter automatiquement les données depuis des pages web à l’aide d’un robot de scraping, permettant de récupérer les données à grande échelle très rapidement. En même temps, des fonctionnalités supplémentaires comme RegEx ou XPath sont mises en service pour obtenir les données structurées et précises.
Le web scraping gratuit fonctionne comme suit :
Tout d’abord, un robot de scraping simule l’acte de navigation humaine sur le site web. Après qu’on entre l’URL cible, le robot envoie une requête au serveur et récupère les informations dans le fichier HTML.
Ensuite, quand le robot a déjà saisi le code source HTML, il va atteindre la partie où se trouvent les données désirées et les analyser comme il est programmé dans le code de scraping.
À la fin, l’ensemble des données extraites sera nettoyé et structuré en fonction de la configuration du robot. Jusque là, les données sont prêtes à être téléchargées ou exportées dans votre base de données.
Comment choisir un bon outil de scraping
Lorsque vous choisissez un outil de scraping pour scraper un site, plusieurs critères essentiels doivent guider votre décision, surtout si vous recherchez un logiciel de scraping gratuit ou une solution à faible coût.
- La compatibilité du dispositif est fondamentale : certains outils de scraping gratuits supportent uniquement Windows, tandis que d’autres, comme Octoparse, sont aussi disponibles pour Mac ou Linux, voire en mode Cloud. Cela permet de s’adapter à toutes les configurations professionnelles ou personnelles.
- La capacité à gérer un scraper un site entier ou plusieurs pages en masse est un avantage important, notamment pour extraire rapidement des images, des PDF ou tout autre format de fichiers. Des logiciels de scraping gratuits comme Web Scraper ou Data Miner offrent souvent cette fonctionnalité.
- La facilité d’utilisation représente également un critère clé : un bon outil scraping gratuit doit offrir une interface intuitive, un support dans votre langue, idéalement en français, et des tutoriels accessibles. Avec des outils comme Octoparse ou ParseHub, même les débutants peuvent rapidement prendre en main le logiciel.
- L’automatisation est un autre point crucial : vous devez pouvoir gérer la pagination, utiliser des proxies ou des extensions pour lever certains obstacles, et surtout, pouvoir programmer des tâches de scraping répétitives ou en mode auto-start. La gestion multipages en masse et l’intégration avec d’autres outils d’analyse ou bases de données augmentent aussi la productivité.
- Le rapport coût/bénéfice est vital, surtout si vous optez pour un outil de scraping gratuit ou à faible coût. Il faut vérifier si l’outil gratuit offre suffisamment de fonctionnalités pour couvrir vos besoins ou si une version payante apporte un vrai plus, notamment en termes d’automatisation, de vitesse ou de traitement de gros volumes.
- La disponibilité d’une version sans code est désormais un critère décisif : des outils comme Octoparse ou Instant Data Scraper permettent de scraper sans programmation, tandis que Scrapy ou Puppeteer s’adressent aux développeurs. Identifier votre niveau technique avant de choisir vous évitera une courbe d’apprentissage inutile.
Outils de scraping avec IA : ce qui change en 2026
L’intégration de l’intelligence artificielle dans les outils de scraping a profondément modifié la façon de configurer une extraction. Jusqu’en 2023, paramétrer un scraper demandait de sélectionner manuellement chaque élément HTML à cibler, une étape technique qui freinait les utilisateurs non développeurs.
Depuis, plusieurs outils de scraping gratuits intègrent une détection automatique par IA : l’outil analyse la structure de la page et identifie lui-même les données pertinentes (prix, titres, liens, coordonnées…) sans intervention manuelle. C’est notamment ce que propose Octoparse dans sa version gratuite, avec un modèle IA capable de reconnaître les patterns répétitifs sur n’importe quelle page.
En pratique, cela réduit le temps de configuration d’une tâche de scraping de plusieurs heures à quelques minutes, un avantage décisif pour les utilisateurs qui ne souhaitent pas apprendre le XPath ou les sélecteurs CSS. Pour les développeurs, des outils comme Playwright intègrent désormais des extensions IA pour l’identification automatique des éléments dynamiques.
À retenir : si votre priorité est la rapidité de mise en place sans compétences techniques, privilégiez un outil de scraping avec détection IA intégrée. Si vous avez besoin de contrôle précis sur chaque champ, les frameworks open source restent plus adaptés.
Quel scraper gratuit choisir selon votre profil ?
Pour vous aider à décider rapidement, voici une synthèse par profil utilisateur :
- Débutant sans expérience technique → Octoparse ou Instant Data Scraper : prise en main en moins de 10 minutes, aucun code requis.
- Utilisateur ponctuel (extraction unique) → Instant Data Scraper ou Data Scraper : gratuit, sans installation lourde, résultat en quelques clics.
- Professionnel avec besoins réguliers → Octoparse (version gratuite ou Cloud) ou ParseHub : automatisation, planification et export structuré.
- Développeur → Python/BeautifulSoup, Scrapy ou Puppeteer : contrôle total, scalabilité maximale, intégration dans vos pipelines de données.
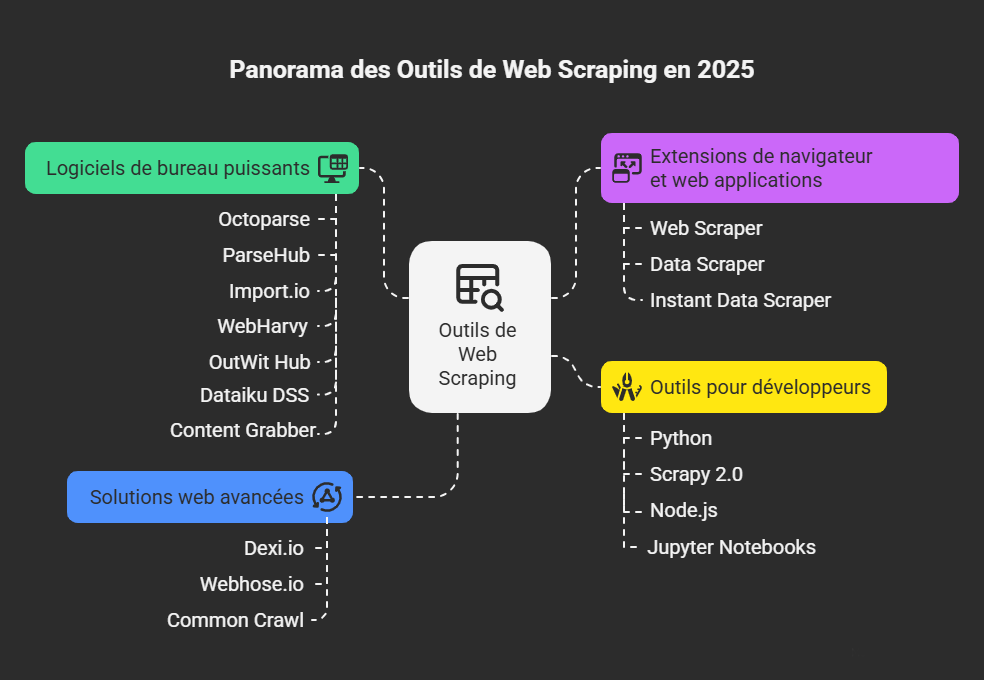
Panorama des outils de scraping en 2026
1. Logiciels de scraping gratuits sans code
- Octoparse est la référence en matière de web scraping gratuit sans code en 2026, disponible en version entièrement gratuite, sans limite de temps et sans carte bancaire. Il intègre une IA avancée qui détecte automatiquement les données à extraire : il suffit de cliquer sur les éléments souhaités, sans écrire une seule ligne de code. La gestion de la pagination, le scraping en masse et plus de 500 modèles prédéfinis pour les sites populaires (Amazon, LinkedIn, Google Maps…) en font l’outil le plus complet de cette liste. Si vous cherchez à extraire des données d’un site web vers Excel, Octoparse reste la solution la plus directe. Disponible sur Windows et Mac, avec une version cloud pour planifier vos collectes en arrière-plan, Octoparse propose également un serveur MCP pour intégrer le scraping directement dans vos workflows IA (Claude, ChatGPT…) sans quitter votre environnement de travail. Limite gratuite : aucune limite de temps sur la version de base ; pour le détail complet des fonctions incluses, consultez ce que permet la version gratuite d’Octoparse.
- ParseHub est un logiciel de scraping disponible en version gratuite, très apprécié pour sa simplicité d’utilisation. Il convient parfaitement aux utilisateurs qui n’ont pas de connaissances techniques approfondies, tout en offrant la possibilité d’aspirer un site même avec des pages utilisant AJAX ou JavaScript. Limite gratuite : 5 projets actifs maximum, 200 pages par run, sans accès au mode cloud.
- Import.io est une solution SaaS largement utilisée dans le domaine de l’e-commerce pour la collecte de données à grande échelle. Sa plateforme offre de nombreuses possibilités d’intégration et est reconnue comme un outil scraping gratuit efficace pour automatiser la récupération de données massives. Limite gratuite : essai gratuit disponible, fonctionnalités complètes réservées aux plans payants.
- WebHarvy se distingue par son interface graphique intuitive, ce qui permet d’extraire des données facilement sans programmation. C’est une option intéressante pour ceux qui cherchent un outil simple mais performant. Limite gratuite : version d’essai disponible, licence complète payante à partir de 99 $.
- OutWit Hub, quant à lui, propose une interface conviviale permettant d’extraire rapidement des données ciblées. Son avantage réside dans sa facilité d’utilisation pour réaliser des extractions sans configuration complexe. Limite gratuite : version de base gratuite disponible, fonctions avancées d’export réservées à la version Pro.
- Dataiku DSS est une plateforme de niveau avancé qui combine web scraping et analyse de données. Idéal pour automatiser des traitements complexes et gérer de gros volumes, c’est un outil adapté aux projets professionnels nécessitant une intégration poussée. Limite gratuite : version Free disponible pour un usage individuel, limitée en connecteurs et sans support prioritaire.
- Content Grabber est une solution particulièrement puissante, conçue pour le scraping en masse. Elle est spécialisée dans la collecte de données massives à partir de sites très complexes, en offrant des performances optimales pour les besoins professionnels les plus exigeants. Limite gratuite : version gratuite limitée à un usage non commercial, fonctions avancées réservées aux licences payantes.
2. Extensions Chrome gratuites pour scraper
Si vous cherchez spécifiquement un outil pour Chrome, consultez notre comparatif dédié : les meilleurs web scrapers pour Chrome.
- Web Scraper est une extension Chrome gratuite, très populaire pour scraper un site en configurant un sitemap. Cette solution est pratique pour ceux qui cherchent un outil de scraping gratuit facile à utiliser tout en bénéficiant d’un bon contrôle sur la structure du site. Limite gratuite : scraping local uniquement, le mode cloud (planification et export automatique) est réservé à la version payante.
- Data Scraper est une extension gratuite compatible avec Chrome et Firefox, très efficace pour extraire des données en quelques clics sans aucune configuration. Elle est particulièrement adaptée pour scraper un site rapidement, notamment pour extraire des tableaux ou des listes, sans nécessiter de compétences approfondies. Limite gratuite : 500 lignes par extraction, pas d’automatisation planifiée.
- Instant Data Scraper est une extension Chrome 100% gratuite, parfaite pour des opérations rapides. Avec cet outil, vous pouvez extraire les données d’un site en quelques secondes, sans configuration complexe ni programmation. C’est le meilleur web scraper gratuit pour un usage ponctuel : idéal pour extraire rapidement un tableau ou une liste sans installation. Limite gratuite : entièrement gratuit, mais sans planification, sans export automatique et sans gestion de la pagination avancée. Pour des besoins plus réguliers ou des volumes importants, un outil comme Octoparse offre bien plus de contrôle et une version gratuite sans limite de temps.
Les protections anti-scraping restent le principal obstacle lors d’une extraction automatisée : notre guide sur les outils pour contourner les CAPTCHAs détaille les méthodes les plus efficaces en 2026.
3. Outils de web scraping pour développeurs
- Python (BeautifulSoup, Selenium, Playwright) est une des meilleures options pour ceux qui maîtrisent la programmation. Ces outils permettent de scraper un site avec un contrôle précis sur la récupération des données, tout en restant dans une démarche de web scraping gratuit. Ils offrent une flexibilité exceptionnelle pour automatiser des tâches complexes et personnalisées. Pour une comparaison détaillée entre BeautifulSoup et une solution sans code, consultez notre analyse BeautifulSoup vs Octoparse. Limite gratuite : entièrement gratuit et open source, sans aucune restriction technique, mais nécessite un environnement Python et un hébergement pour les tâches planifiées.
- Scrapy est un framework open source entièrement gratuit, puissant pour réaliser du web scraping à grande échelle. Son architecture modulaire facilite la gestion de pages très structurées ou dynamiques, ce qui en fait un excellent choix si vous souhaitez scraper un site complexe avec précision. Limite gratuite : aucune restriction, entièrement open source, hébergement et infrastructure à gérer soi-même.
- Node.js (Puppeteer) est une bibliothèque efficace pour scraper un site dynamique, notamment lorsque le contenu est chargé via des scripts JavaScript. Elle permet de simuler un navigateur complet pour extraire toutes sortes de données, idéale pour les experts en web scraping qui cherchent une solution flexible et performante. Limite gratuite : entièrement gratuit et open source, nécessite Node.js et un hébergement dédié pour les collectes planifiées.
- Jupyter Notebooks est une plateforme pratique pour tester rapidement des scripts de web scraping en Python. C’est un excellent environnement pour expérimenter, automatiser des tâches ciblées et affiner votre approche de scraping à votre rythme. Limite gratuite : entièrement gratuit en local, version cloud disponible via JupyterHub ou Google Colab.
4. Solutions web avancées et APIs de scraping
- Dexi.io est une solution cloud destinée aux utilisateurs ayant des bases en programmation. Il propose trois types de robots configurables (Extractor, Crawler et Pipes) pour couvrir différents cas d’extraction, ainsi que des proxies anonymes intégrés. Les données peuvent être exportées en JSON ou CSV. La courbe de prise en main est plus prononcée que pour les outils sans code. Limite gratuite : données hébergées sur les serveurs Dexi.io pendant deux semaines avant archivage automatique, collecte en temps réel réservée aux plans payants.
- Webz.io est une API de collecte de données en temps réel, capable d’agréger des contenus publics depuis des sources mondiales dans de nombreuses langues. Elle supporte les formats XML, JSON et RSS, avec des filtres avancés pour cibler précisément les données souhaitées. Limite gratuite : 1 000 requêtes HTTP par mois incluses dans le plan gratuit, volume supérieur réservé aux plans payants.
- Common Crawl est une ressource open source entièrement gratuite, contenant des milliards de pages web accessibles à tous. Les spécialistes peuvent l’utiliser pour du web scraping à très grande échelle, notamment dans le cadre de projets de recherche ou de veille approfondie. Limite gratuite : aucune restriction d’accès, mais les données sont fournies en snapshots périodiques et non en temps réel, ce qui la rend inadaptée aux collectes nécessitant une fraîcheur des données.
Une fois vos données collectées, l’étape suivante consiste à les structurer correctement : notre guide sur le data cleaning couvre les méthodes les plus efficaces pour nettoyer automatiquement vos données scrapées.
N’hésitez pas à utiliser cette infographie sur votre site, à condition de mentionner la source et de créer un lien vers l’URL de notre blog à l’aide du code d’intégration ci-dessous :
FAQ : outils de scraping gratuits
- Quel est le meilleur scraper gratuit ?
Cela dépend de votre profil. Pour un usage sans code, Octoparse est la référence : version gratuite sans limite de temps, IA intégrée et 200+ modèles prêts à l’emploi. Pour une extraction ponctuelle depuis Chrome, Instant Data Scraper est la solution la plus rapide. Pour les développeurs, Scrapy ou BeautifulSoup offrent le plus de flexibilité.
- Quel est le meilleur extracteur web gratuit ?
Octoparse se distingue par sa version gratuite complète, sa compatibilité Windows/Mac/Cloud et sa capacité à gérer des sites complexes (JavaScript, pagination, authentification) sans écrire une ligne de code.
- Est-ce que le scraping est légal ?
Le web scraping est légal sur les données publiquement accessibles, à condition de respecter les CGU du site, le RGPD et de ne pas saturer les serveurs. Certains sites l’interdisent explicitement dans leur fichier robots.txt : il est recommandé de le vérifier avant de lancer une collecte.
- Quel est le meilleur site web pour faire du web scraping ?
Pour commencer sans coder, octoparse.fr propose un outil gratuit, des tutoriels en français et plus de 200 modèles pour les sites populaires (Amazon, Google Maps, LinkedIn…). C’est le point d’entrée le plus accessible pour les utilisateurs francophones.
- Comment scraper gratuitement sans coder ?
La méthode la plus simple en 2026 est d’utiliser une extension Chrome comme Instant Data Scraper pour des extractions ponctuelles, ou un logiciel de bureau comme Octoparse pour des collectes récurrentes et structurées. Dans les deux cas, aucune ligne de code n’est nécessaire : vous cliquez sur les éléments à extraire, l’outil construit la tâche automatiquement.
- Quel est le meilleur outil de scraping IA en 2026 ?
Les outils qui intègrent une IA pour la détection automatique des données gagnent du terrain : Octoparse et ParseHub proposent tous une détection assistée. Octoparse se distingue par sa version gratuite sans limite de temps et sa compatibilité multi-OS : l’IA détecte automatiquement les champs à extraire sans paramétrage manuel.
- Quelle est la différence entre un scraper gratuit et payant ?
Les scrapers gratuits couvrent largement les besoins d’évaluation et les collectes ponctuelles. Les limites apparaissent dès que le volume augmente : plafond de pages par run, absence de planification automatique, pas de rotation de proxies intégrée et données hébergées temporairement. Les versions payantes lèvent ces contraintes et ajoutent généralement le support prioritaire, l’accès API et des garanties de taux de succès sur les sites protégés. Pour la plupart des utilisateurs débutants ou intermédiaires, une version gratuite comme celle d’Octoparse suffit pour démarrer sans engagement.
Quel web scraper gratuit choisir en 2026 ?
En 2026, il existe un outil de scraping gratuit pour chaque profil : Octoparse et ParseHub pour ceux qui veulent scraper sans coder, Python/Scrapy pour les développeurs, et des extensions Chrome comme Instant Data Scraper ou Web Scraper pour les besoins ponctuels. Quel que soit votre niveau, le web scraping gratuit est désormais accessible à tous.
Sur le plan légal, le web scraping est généralement autorisé sur les données publiques, à condition de respecter le RGPD, les CGU du site cible et de ne pas surcharger les serveurs. En cas de doute, privilégiez un outil qui intègre des protections natives comme la rotation de proxies. En 2026, la tendance de fond est à l’intégration des scrapers dans des workflows IA : des solutions comme Octoparse MCP permettent désormais de connecter directement la collecte de données à vos agents IA, sans passer par des exports manuels.
Commencez avec l’outil qui correspond à votre niveau technique et faites évoluer votre stack au fur et à mesure de vos besoins. Vous souhaitez commencer sans risque ? Essayez Octoparse gratuitement : aucune carte bancaire requise, aucune limite de temps. Testez directement sur votre site cible et voyez les résultats en quelques minutes.
Une prochaine étape naturelle consiste à structurer vos données : notre tutoriel sur extraire des données d’un site web vers Excel vous guide étape par étape.



