Dans l’ère informatique, nous savons tous à quel point les données sont importantes, mais pour la plupart d’entre nous, c’est un casse-tête d’écrire le code en utilisant python pour effectuer l’extraction de données à grande échelle. Octoparse est l’outil ultime pour les non-codeurs qui ont besoin d’un grand nombre de données. Cet outil de web scraping a gagné plus de trois millions d’utilisateurs dans le monde entier qui l’utilisent pour l’analyse de sentiment, le référencement naturel, le marketing, l’e-commerce, l’informatique, l’immobilier, l’hôtellerie et beaucoup d’autres. Avec une base de données précise à portée de main, vous serez en mesure d’effectuer des analyses de données, des stratégies de marketing, des analyses de sentiments, des campagnes publicitaires, la génération de prospects et bien plus encore.
L’équipe d’Octoparse est convaincue que le web scraping doit être accessible à tous afin d’exploiter la puissance des données. Pour atteindre cet objectif, l’équipe d’Octoparse n’a jamais ralenti ses pas pour rendre l’extraction de données plus simple et facile.
Dans cet article, nous allons vous présenter une fonctionnalité puissante: Octoparse templates (modèle de web scraping), permettant d’obtenir les données des sites Web en trois clics.
Conseils : Télécharger Octoparse pour commencer votre première découverte des modèles de web scraping.
Octoparse templates pour extraire facilement des données de n’importe quel site Web
Le Modèle de Web Scraping désigne un ensemble de tâches pré-construites créées par l’équipe technique d’Octoparse qui sont prêtes à l’emploi et tout le monde peut les utiliser sans avoir à configurer de règles de scraping ni à écrire de codes. Il suffit aux utilisateurs d’entrer seulement quelques paramètres, par exemple, l’URL cible, les mots-clés, le nombre de pages à parcourrir pour que le robot d’Octoparse exécute le web scraping automatiquement.
Il se peut que vous posiez un autre problème important :
— Les modèles de web scraping sont-ils gratuits ?
— Oui pour la majorité écrasante de modèles, et non pour une petite partie quand le modèle est difficile à développer ou que le coût de maintenance est assez haute.
Ce facteur est mentionné clairement dans l’introduction de chaque modèle que vous pouvez lire avant de l’utiliser et si vous avez des questions sur cela, n’hésitez pas à contacter le support.
Par exemple, la capture suivante est une introduction du modèle Google Maps où on peut clairement voir le tarif : 0.2$ pour un mille de lignes de données.
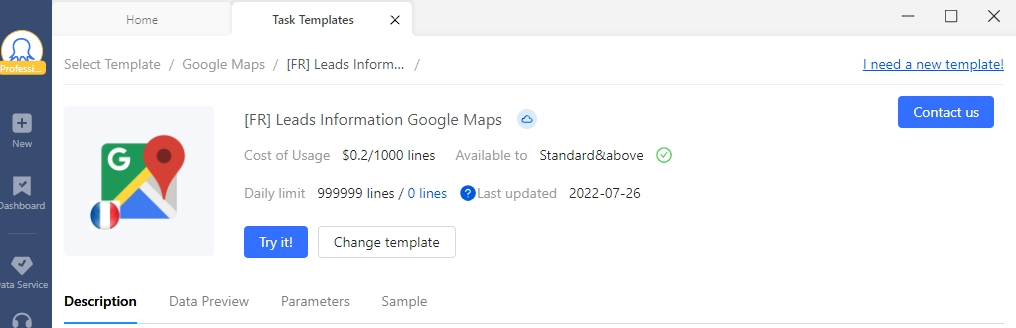
Qu’est-ce qui rend le “Template Mode” si spécial ?
Un problème très fréquent parmi ceux qui intéressés par le web scraping : Quel est le niveau de compétence technique requis pour effectuer le web scraping ? La réponse est “Rien” si on a recours aux modèles de web scraping.
Octoparse templates se confirment comme la solution idéale pour les personnes non-techniques. Il suffit d’entrer des paramètres nécessaires, et Octoparse s’occupera de tout à partir de là.
En résumé, cinq étapes simples pour obtenir autant de données que vous voulez en quelques minutes
Étape 1 Trouver le modèle que vous souhaitez utiliser : vous pouvez effectuer une recherche par les mots-clés dans la barre de recherche ou chercher le modèle par les catégories.
Étape 2 Lire l’introduction détaillée sur le modèle : savoir les paramètres à remplir, les données à récupérer pour s’assurer que ce modèle convient bien à vos besoins.
Étape 3 Entrer les paramètres que Octoparse demande à remplir selon les instructions : il s’agit souvent de l’URL cible, les mots-clés, le nombre de pages à parcourrir, etc. Attention de bien suivre les instructions pour entrer les paramètres corrects.
Étape 4 Cliquer sur “Save” et puis “Run”
Étape 5 Exporter les données récupérées : vers Excel, CSV, Json ou votre base de données via API
Un exemple d’utiliser le modèle de web scraping : Comment obtenir des millions d’annonces sur leboncoin.fr en quelques clics
Vous pouvez aussi regarder un peu ce vidéo pour comprendre directement à quel degré le modèle de web scraping facilite l’extraction de données Amazon.
A qui Octoparse template mode est-il destiné ?
Tout le monde !
Oui, pour tous ceux qui veulent obtenir des données rapidement et facilement.
Combien de modèles Octoparse offre-t-il ?
Il est à noter que les modèles sont constamment mis à jour. Vous pouvez nous suivre sur Twitter pour recevoir les annonces et les mises à jours à temps.
E-commerce
Voilà une liste de modèles populaires mais attention que la liste n’est pas encore le tout. Jusque maintenant, les modèles d’Octoparse couvrent principalement les catégories suivantes :
Ces dernières années, le web scraping est largement employé dans l’industrie d’e-commerce. Quand l’e-commerce prospère et des tonnes de données se génèrent chaque jour, le scraping peut vous aider à obtenir les données sur les produits en quelques clics. Voyons les modèles qui couvrent les plateformes d’e-commerce populaires.
Amazon – Il s’agit d’une plateforme d’e-commerce multinationale. Son gigantesque réservoir de données comprend un nombre infini d’informations sur les produits. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire les informations de base sur les produits, comme nom du produit, prix, ASIN, images, descriptions, catégories, expédition, livraison, produits commentés par les clients, notations, nombre de commentaires, listes des meilleures ventes Amazon et URL des pages.
eBay – Une plateforme d’achat en ligne qui compte plus de 170 millions d’acheteurs dans de nombreux pays. Le site est surtout connu pour ses ventes aux enchères et ses ventes C2C. Si vous souhaitez démarrer une activité sur eBay, Octoparse est l’outil indispensable pour surveiller les prix, générer des pistes, classer les produits, etc. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire le nom du produit, le numéro du produit, les URL du produit, l’état, le prix, l’inventaire, le nom du vendeur, le lien, le nombre de commentaires positifs sur le produit.
Leboncoin – Leboncoin.fr est le premier site français de petites annonces en ligne et jouit depuis sa naissance de la renommée de ” le plus grand vide-grenier en France “. En tant que plateforme de consommation collaborative, leboncoin.fr propose un espace qui est ouvert gratuitement aux particuliers. Donc, ceux qui veulent vendre ou acheter quelque chose se réunissent ici pour déposer les différentes annonces. Avec le modèle de scraping web Octoparse, vous seriez en mesure de :
Extraire les informations sur des annonces, comme catégorie, mot-clé, titre, prix, détail, description, location du vendeur, URL des annonces.
Bestbuy – Barron’s a nommé Best Buy n° 1 sur sa liste des 100 entreprises les plus durables pour 2019. Les différents produits, notamment les logiciels, les jeux vidéo, les caméras numériques, les autoradios, les téléphones portables, etc. Octoparse est un excellent outil pour la surveillance des prix sur Bestbuy. Avec le modèle de scraping web Octoparse, vous seriez en mesure de :
Extraire les informations de base sur les produits, notamment les noms, les numéros de modèle, les prix, les UGS, les URL des produits, les URL des images, les numéros de page, l’heure d’extraction, la page de liste actuelle, le titre de la page, l’URL de la page, le nombre de commentaires sur les produits et leurs URL.
AliExpress – Aliexpress.com est un site chinois de commerce en ligne spécialisé dans la vente de produits à prix bas, aux particuliers et à l’international. Il fait partie du top 50 des sites les plus visités dans le monde.
Extraire les informations de base sur les produits : nom du produit, description, image, prix, notations, nombre de produits vendus, nom et URL des magasins et d’autres.
Les modèles de scraping d’Octoparse couvrent beaucoup d’autres sites d’e-commerce, comme Shopee, Orange, Allopeneus, Leslibraires, Shein, Otto, et beaucoup d’autres. En effet, si les sites que vous souhaitez scraper ne sont pas inclus dans la liste de modèle, vous pouvez envoyer une demande au support, et nous nous en occuperons après des évaluations
Booking.com – Il s’agit d’un site Web d’agrégation d’informations sur les voyages. Avec près de 30 millions d’inscriptions dans plus de 150 000 destinations à travers 228 pays et territoires, il s’agit d’une source de données géante pour les études de marché et les enquêtes commerciales. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur l’hôtel, notamment le nom, l’adresse, les étoiles, les équipements, les informations sur le petit-déjeuner, le nombre d’avis, la note moyenne, le nombre de chambres, les URL des images et l’URL de la page.
Voyage
Airbnb – Il s’agit d’un marché en ligne américain et d’une société de services d’accueil. Elle permet aux gens de lister des propriétés. Grâce à la technique du web scraping, il est possible de recueillir des informations, notamment sur la démographie, la population et le logement. Il est crucial pour les agents immobiliers et les agences de voyage de recueillir ces informations en temps voulu. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur l’hôtel, notamment : titre, emplacement, propriété, URL des pages, nombre de clients, nombre de chambres, nombre de lits, nombre de salles de bain, prix, notation, nombre d’avis, équipements, couchage, hôte, heure de connexion, langues, taux de réponse, heure de réponse, heure actuelle et URL des images.
Tripadvisor – Avec plus de 570 millions de commentaires et d’avis portant sur 1,2 million d’entreprises du secteur de l’hôtellerie, TripAdvisor traite un grand nombre de données. Dans le secteur de l’hôtellerie, il est important pour une entreprise de savoir comment optimiser les prix et faire de la publicité de manière judicieuse. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur l’hôtel, notamment le nom de l’hôtel, son emplacement, le nombre d’avis, le classement, l’URL de la page Web, le numéro de téléphone, les équipements, les caractéristiques de la chambre, les notes, la notation de l’emplacement, la notation de la propreté, la notation du service, la notation du rapport qualité-prix, l’avantage pour les randonneurs, le nombre de restaurants, le nombre d’attractions, les URL des images.
Réseaux sociaux
Twitter – 500 millions de tweets sont publiés chaque jour par 326 millions d’utilisateurs. C’est une mine d’or de données, notamment sur le divertissement, les sports, les célébrités, les actualités, les finances, etc. C’est un site populaire pour rechercher et analyser l’économie, la société et la politique. Avec le modèle de scraping web Octoparse, vous serez en mesure de:
Extraire des informations de base sur les publications, notamment le nom d’utilisateur Twitter, l’ID utilisateur, le contenu des tweets, la date de publication, les commentaires, le nombre de retweets, le nombre de likes, l’URL de l’image, l’URL du tweet et l’URL de la vidéo.
Youtube – Le site de vidéos le plus populaire au monde. Comment exploiter ce gigantesque réservoir de sources pour créer votre propre index d’informations avec des données précieuses? Quelles sont les vidéos les plus tendance? Comment les gens perçoivent-ils un certain type de vidéos et plus encore? Le web scraping peut vous aider à répondre à ces questions. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire les informations de base du message, notamment le titre, la description et le lien de la vidéo, la date de publication, le nombre total de vues, le lien de la chaîne et le nom de la chaîne.
TikTok – Tiktok est une plateforme de partage de vidéos qui connaît la croissance la plus rapide ces dernières années. Chaque mois, plus d’un milliard de personnes s’y retrouvent pour regarder ou partager des vidéos de toutes sortes. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire les informations sur les vidéos, comme URL des vidéos, poster, date de vidéo, contenu, tags, nombre de likes, nombre de commentaires, commenteur, date de commenter, etc.
Business Contact – C’est l’un des modèles le plus utilisés parmi les utilisateurs d’Octoparse. Après des URLs sont entrés, ce modèle va scraper les informations commerciales accessibles sur cette page. Vous risquez de rencontrer des données innormales parce que ce modèle utilise le RegEx pour chercher les informations désirées à partir du code de source. Grâce à ce modèle, vous pouvez :
Extraire email, compte Twitter, compte Facebook, compte Linkedin, compte Instagram.
Moteur de recherche
Des millions de pages web et de contenus sont mis en ligne chaque jour. Même si les moteurs de recherche peuvent aider à cibler les recherches plus rapidement, vous devez toujours cliquer manuellement sur chaque résultat pour filtrer celui qui vous intéresse. Pour optimiser ce processus, Octoparse peut extraire les informations ciblées et les exporter dans un format structuré. Quoi de mieux que de disposer d’une machine à filtrer les ressources qui vous fait gagner un temps précieux ?
Google Search – Avec les plus grands moteurs de recherche, l’information est écrasante. Pour éviter de se perdre, le web scraping peut nous aider à créer notre propre base de données de tous les sites. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur les résultats de recherche, notamment le titre, l’URL et la méta-description.
Bing – En tant que troisième plus grand moteur de recherche. Bing partage ses ressources avec Google, mais les résultats de recherche sont différents. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur les résultats de recherche, notamment le titre, l’URL et la méta-description.
Annuaire
CrunchBase – Il s’agit d’une plateforme de premier plan pour découvrir des talents. Elle compte plus de 50 millions de professionnels, dont des investisseurs, des spécialistes des études de marché, des vendeurs, des entrepreneurs et bien d’autres encore. Pour les RH, le web scraping est incroyable pour vous aider à extraire les bons candidats. Avec le modèle de scraping web Octoparse, vous serez en mesure de
Extraire des informations sur les entreprises, notamment le nom, l’introduction, les catégories, la date de création, le statut opérationnel, le nombre d’employés, le statut d’introduction en bourse, le type d’entreprise, l’URL du site Web, l’URL de Facebook, l’URL de Linkedin, l’URL de Twitter et l’adresse électronique.
Yellowpages(PagesJaunes) – Il s’agit du fournisseur de services et de l’annuaire des entreprises le plus connu depuis des années. Au lieu de l’annuaire téléphonique à l’ancienne, les Pages Jaunes se concentrent désormais sur le marketing numérique. Pour publier une campagne publicitaire, développer votre marque et nouer le dialogue avec vos partenaires commerciaux potentiels, le web scraping peut vous aider à constituer un réservoir de données. Avec le modèle de web scraping d’Octoparse, vous serez en mesure de:
Extraire des informations sur les entreprises, notamment le nom, les sites web, les heures d’ouverture, l’adresse, les heures d’ouverture, le numéro de téléphone, l’adresse électronique, l’évaluation, les catégories, les quartiers, les prix, les méthodes de paiement et d’autres informations.
Yelp – Des millions de personnes recherchent une entreprise pour toutes sortes de raisons. La communauté possède des données riches en photos, avis, informations commerciales. C’est l’endroit que vous devez explorer pour connaître votre entreprise et vos concurrents. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Extraire des informations sur les entreprises, notamment le nom, la note en étoiles, le nombre d’avis, les tags, le numéro de téléphone, l’adresse, l’URL du site web et les heures d’ouverture.
Societe.com – Ce site propose depuis 20 ans des informations légales, juridiques et financières gratuites des entreprises française. Avec le modèle de scraping web Octoparse, vous pouvez
Extraire des informations sur les entreprises, notamment le nom, type d’entreprise, SIREN, numéro, URL et d’autres.
On travaille continuellement pour développer des modèles sur des sites d’annuaires français.
Commentaires
BestBuy Review – Si vous êtes un détaillant en électronique, vous devriez garder un œil sur Bestbuy. Outre l’analyse des changements de prix, quel est le produit le plus populaire et ce qu’en pensent les clients ? Il est facile de mener une analyse du sentiment des produits avec Octoparse. Avec le modèle de scraping Web d’Octoparse, vous pouvez:
Extraire des avis comprenant : le nom du produit, le numéro de modèle, l’UGS, les notes, le nombre d’avis, le taux de recommandation, le compte, les brefs commentaires, l’heure de publication, la recommandation ou non, les votes positifs utiles, les votes négatifs, l’URL de la page, la description et le contenu de l’avis.
Google Play – Selon Statista, il y a plus de 2,6 millions d’applications dans le Google Play Store. Pour les développeurs d’applications, il est essentiel de savoir comment créer une application de haut niveau. Par conséquent, nous devons connaître les caractéristiques communes aux meilleures applications. Il est facile d’avoir une base de données des applications les plus vendues, des applications les plus rentables, des jeux les plus populaires, des jeux les plus vendus, des jeux les plus rentables. Avec le modèle de scraping web Octoparse, vous serez en mesure de :
Récupérer les avis sur les APP, y compris : le nom de l’application, le nom de l’entreprise, la catégorie, le nom de l’utilisateur, l’heure de publication de l’avis, les commentaires, la notation par étoiles de l’avis, l’URL, l’URL de la catégorie.
Emploi
Indeed – Indeed est un moteur de recherche d’emploi qui est lancé aux Etats-Unis et maintenant disponible dans plus de 50 pays. Ces données sont d’une grande valeur pour tant les demandeurs d’emploi ou les recruteurs que les créateurs de jobboard. De plus, les marketers et chercheurs peuvent avoir de l’intérêt pour ces données. Avec les modèles d’Octoparse, vous pouvez
Glassdoor – Comme Indeed, Glassdoor rassemble ceux qui lancent des offres d’emploi et ceux qui demandent un emploi. Ainsi, un nombre immense de données d’emploi sont accessibles sur ce site. Octoparse développe un modèle surtout pour facilter la collecte de ces données comme nom d’entreprise, évaluation, titre du poste, salaire proposé, date du poste, description du poste, etc.



