Le Web scraping nous apporte certainement des avantages. Il est rapide, rentable et permet de collecter des données à partir de sites Web avec un taux de précision de plus de 90 %. Il vous libère des tâches interminables de copier-coller. Cependant, le web scraping comporte également des limites et même des risques qui méritent d’une attention. Cet article va présenter les 7 principales limites du web scraping que vous devez connaître.
Qu’est-ce que le web scraping et à quoi sert-il ?
Le web scraping est une technique utilisée pour extraire des informations de sites web à une vitesse rapide. Il s’agit de l’une des premières étapes de l’analyse, de la visualisation et de l’exploration des données, puisque la préparation des données est une étape préalable à toute visualisation ou analyse ultérieure. C’est pourquoi le web scraping devient un sujet chaud parmi les entreprises qui recherchent une growth.
Quelle est la meilleure façon d’extraire des données du Web ?
Il existe quelques techniques courantes pour extraire des données de pages Web. Vous pouvez soit construire votre propre robot d’exploration à l’aide de langages de programmation, soit externaliser vos projets d’exploration du Web, soit utiliser un outil Web scraping. Chacun a des avantages et des limites. Sans un contexte spécifique, il n’existe pas de “meilleure façon de faire du scraping”. Cela dépend de vos connaissances de base en matière de codage, du temps dont vous disposez et de votre budget financier.
> Par exemple, si vous êtes un codeur professionnel et que vous avez confiance en vos compétences en matière de codage, vous pouvez certainement récupérer des données par vous-même. Mais comme chaque site Web a besoin d’un crawler, vous devrez en construire plusieurs pour différents sites. Cela peut prendre beaucoup de temps. Et vous devez avoir des connaissances suffisantes en programmation pour assurer la maintenance des crawlers. Pensez-y.
> Si vous êtes propriétaire d’une entreprise disposant d’un gros budget et ayant besoin de données précises, la situation sera différente. Oubliez la programmation, engagez simplement un groupe d’ingénieurs ou confiez votre projet à des professionnels.
> En parlant d’externalisation, vous trouverez peut-être des indépendants en ligne qui proposent ces services de collecte de données. Le prix unitaire semble tout à fait abordable. Les statistiques montrent que pour scraper 6000 produits d’Amazon, les tarifs des sociétés de web scraping s’élèvent en moyenne à 250 $ pour l’installation initiale et à 177 $ pour la maintenance mensuelle.
> Si vous êtes propriétaire d’une petite entreprise, ou simplement un non-codeur ayant besoin de données, le meilleur choix est de choisir un outil de scraping adapté à vos besoins. Pour une référence rapide, vous pouvez consulter cette liste des 30 meilleurs logiciels de scraping web.
Quelles sont les limites de scraping web ?
1. La courbe d’apprentissage
Même l’outil de scraping le plus simple demande du temps pour être maîtrisé. Certains outils, comme Apify, nécessitent encore des connaissances en codage pour être utilisés. Certains outils faciles à utiliser pour les non-codeurs peuvent prendre des semaines à apprendre. Pour réussir à gratter des sites Web, des connaissances sur XPath, HTML et AJAX sont nécessaires. Jusqu’à présent, le moyen le plus simple de scraper des sites Web est d’utiliser des modèles de scraping Web préétablis pour extraire des données en quelques clics. Pour commencer, je vous recommende Octoparse qui travaill toujours pour rendre le web scraping accessible à tous. Par exemple, il met à jour son algorithme de détection automatique en août 2023 dans la fin de mieux et plus précisément détecter les structures des pages Web, facilitant la configuration de projet de web scraping.
2. La structure des sites web change fréquemment
Les données extraites sont organisées en fonction de la structure du site Web. Il arrive que vous revisitiez un site et que vous constatiez que la page a été modifiée. Certains concepteurs mettent constamment à jour les sites Web pour améliorer l’interface utilisateur, d’autres par souci d’éviter le scraping. La modification peut être aussi minime qu’un changement de position d’un bouton, ou un changement radical de la mise en page globale. Même un changement mineur peut altérer vos données. Comme les scraper sont construits à la base de l’ancien site, vous devez ajuster vos crawlers toutes les quelques semaines pour obtenir des données correctes.
3. Il n’est pas facile de gérer des sites web complexes
Voici un autre défi technique délicat. Si l’on considère le web scraping en général, 50% des sites web sont faciles à scraper, 30% sont modérés, et les derniers 20% sont plutôt difficiles à scraper. Certains outils de scraping sont conçus pour extraire des données de sites Web simples. Pourtant, de nos jours, de plus en plus de sites Web commencent à inclure des éléments dynamiques tels que AJAX. De grands sites comme Twitter appliquent le défilement infini, et certains sites Web demandent aux utilisateurs de cliquer sur le bouton “Charger plus” pour continuer à charger le contenu. Dans ce cas, les utilisateurs ont besoin d’un outil de scraping plus fonctionnel.
4. Il est beaucoup plus difficile d’extraire des données à grande échelle
Certains outils ne sont pas en mesure d’extraire des millions de données, car ils ne peuvent gérer qu’un scraping à petite échelle. Cela pose des problèmes aux propriétaires d’entreprises de commerce électronique qui ont besoin de millions de lignes de données régulières alimentant directement leur base de données. Les outils de scraping basés sur le cloud, comme Octoparse et Web Scraper, sont très performants en termes d’extraction de données à grande échelle. Les tâches s’exécutent sur plusieurs serveurs Cloud. Vous bénéficiez d’une vitesse rapide et d’un espace gigantesque pour la conservation des données.
5. Un outil de scraping web n’est pas omnipotent
Quels types de données peuvent être extraits ? Principalement des textes et des URL.
Les outils avancés peuvent extraire les textes du code source (HTML interne et externe) et utiliser des expressions régulières pour les reformater. Pour les images, c’est également possible de les télécharger par lot.
En outre, il est important de noter que la plupart des outils de scraping Web ne sont pas capables d’explorer les PDF, car ils analysent les éléments HTML pour extraire les données. Pour extraire des données des PDF, vous avez besoin d’autres outils comme Smallpdf et PDFelements.
6. Votre IP peut être bannie par le site web cible
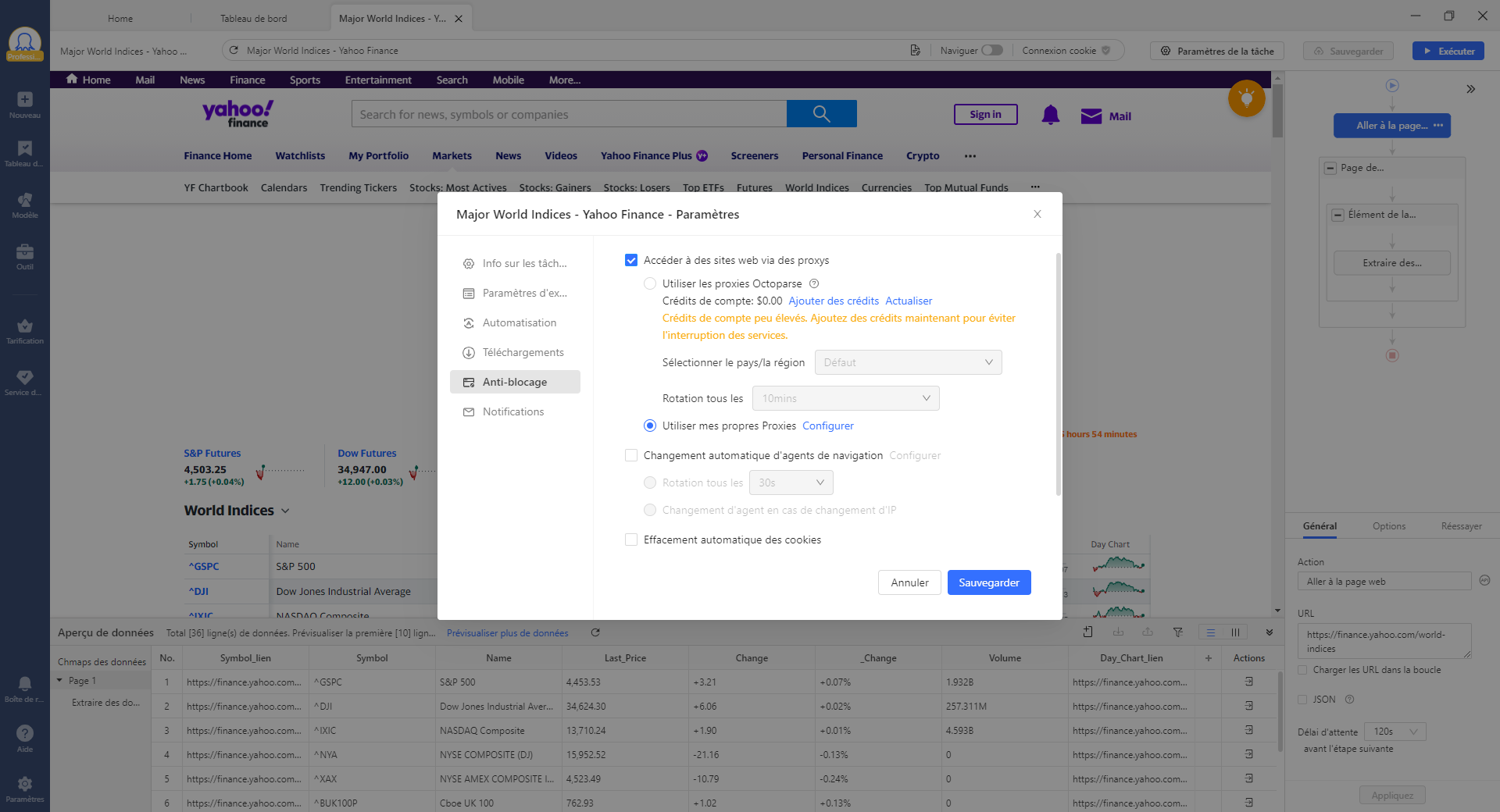
Les captchas dérangent. Vous arrive-t-il de devoir passer un captcha lors d’un scraping sur un site web? Attention, cela peut être le signe d’une détection d’IP. Le scraping intensif d’un site Web entraîne un trafic important, qui peut surcharger un serveur Web et causer des pertes économiques au propriétaire du site. Pour éviter d’être bloqué, il existe de nombreuses astuces. Par exemple, vous pouvez configurer votre outil pour simuler le comportement de navigation normal d’un humain. Ou encore, vous pouvez utiliser les proxies IP et les automatiser au cours de l’exécution de votre projet de scraping. Pas mal d’outils de web scraping supportent déjà cette fonctionnalité. Par exemple, sur Octoparse, vous pouvez choisir d’accéder à des sites via proxies.
7. Il y a même des questions juridiques en jeu
Le web scraping est-il légal ? Un simple “oui” ou “non” ne suffit pas pour répondre à cette question. Disons simplement que… cela dépend. Si vous scrapez des données publiques à des fins académiques, vous ne risquez rien. Mais si vous récupérez des informations privées sur des sites indiquant clairement que le scraping automatisé est interdit, vous risquez d’avoir des problèmes. Instragram et Facebook sont parmi ceux qui indiquent clairement que “nous n’accueillons pas les scrapers ici” dans leur fichier robots.txt/termes et services (ToS). Faites attention à ce que vous faites lorsque vous faites du scraping.
En conclusion
Pour résumer, le web scraping présente de nombreuses limites. Si vous souhaitez obtenir des données à partir de sites Web difficiles à gratter, tels qu’Amazon, vous pouvez vous tourner vers une entreprise de Data-as-a-Service comme Octoparse. C’est de loin la méthode la plus pratique pour extraire des sites web qui appliquent de solides techniques anti-scraping. Un fournisseur DaaS propose un service personnalisé en fonction de vos besoins. En préparant vos données, il vous libère du stress lié à la construction et à la maintenance de vos crawlers. Quel que soit votre secteur d’activité (commerce électronique, médias sociaux, journalisme, finance ou recherche), si vous avez besoin de données, n’hésitez pas à nous contacter, à tout moment.



