Il vous arrive probablement que l’on vous ait demandé de saisir des caractères difficiles à lire quand vous essayez de vous connecter sur un site Web. Les caractères illisibles sont appelés CAPTCHA. Ils constituent déjà un des défis pour les web scrapers.
Aujourd’hui, nous allons parler de 5 choses que vous devez savoir sur CAPTCHA pour vous aider à mieux le contourner pendant le Web scraping. Bien sûr on va présenter une solution tout en un qui est capable de gérer facilement les captchas fréquents.
1. Qu’est-ce que CAPTCHA
Selon Wikipedia, CAPTCHA (test de Turing public complètement automatisé pour séparer les ordinateurs et les humains) est un type de test de défi-réponse utilisé en informatique pour déterminer si l’utilisateur est humain ou non.
Il est couramment utilisé sur Internet, en particulier lors de l’achat de produits en ligne ou de la connexion à un site Web.
2. Comment fonctionne CAPTCHA
La technologie CAPTCHA est basée sur le test de Turing qui est utilisé pour tester si une machine peut penser comme des humains. Le but du CAPTCHA est de poser des questions ou de relever des défis que les ordinateurs sont incapables de relever. D’une manière générale, il montre une chaîne déformée de caractères ou de nombres aléatoires. Cela fonctionne parce qu’un humain qui regarde une image déformée peut lire les mots sans aucun défi, alors qu’un outil de grattage ne les reconnaît pas facilement. Même le système automatisé le plus sophistiqué, qui a été programmé pour numériser une image d’une page de texte imprimé et lire les mots de l’image, a encore des difficultés à lire les mots lorsque les mots sont trop obscurcis ou déformés.
3. Quels sont les types courants de CAPTCHA
CAPTCHA est disponible en plusieurs tailles et de différents types. Les types les plus courants de CAPTCHA sont le CAPTCHA basé sur du texte, le CAPTCHA basé sur l’image et le CAPTCHA basé sur l’audio.
CAPTCHA texte
Un test CAPTCHA basé sur du texte est composé de deux parties simples : une séquence générée aléatoirement de lettres et / ou de chiffres qui apparaissent comme une image déformée, et une zone de texte. Pour réussir le test et prouver votre identité humaine, tapez simplement les caractères que vous voyez dans l’image dans la zone de texte.
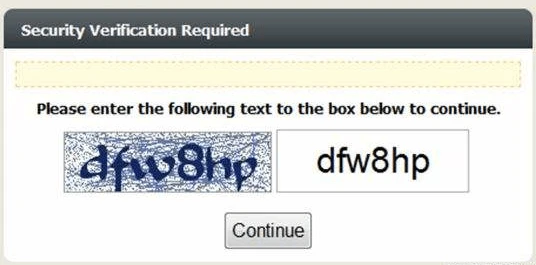
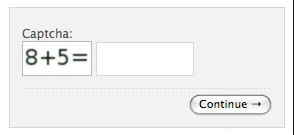
CAPTCHA mathématique
Montrer simplement les personnages n’est pas si difficile pour les robots. Pour augmenter la difficulté, il y a le CAPTCHA mathématique, qui implique un problème mathématique de base avec des nombres faciles à lire, et le CAPTCHA 3D, qui affiche les caractères avec un effet 3D.

CAPTCHA images
CAPTCHA à base d’images fournit généralement aux utilisateurs des images d’objets, d’animaux, de personnes ou de paysages, au lieu d’un texte déformé, pour distinguer un humain d’un programme informatique. Les utilisateurs doivent sélectionner les images correctes qu’ils sont invités à identifier ou faire glisser un bloc dans une image pour la compléter.

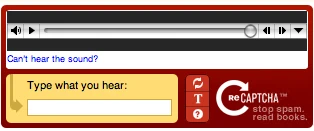
CAPTCHA audio
CAPTCHA audio utilise des mots aléatoires ou des nombres tirés d’enregistrements, les combine et leur ajoute même du bruit. Les utilisateurs doivent entrer les mots ou les nombres dans l’enregistrement. Les CAPTCHA sonores sont plus difficiles à gérer en comparaison avec le contenu et les images CAPTCHA car il n’est pas facile de laisser un robot scraping apprendre à écouter.
ReCaptcha vs. hCaptcha
reCaptcha de Google est utilisé plus largement par les sites Web, dû aux faits que :
- c’est plus facile de configurer et maintenir pour les développeurs
- c’est plus intuitif pour les utilisateurs
- c’est gratuit et Google s’en occupe minutieusement

Il est probabale que vous entendez parler également de hCaptcha. Et il se peut que vous êtes curieux de savoir les différences entre reCaptcha et hCapthca.
En fait, reCaptcha est proposé par Google, et si le service est installé sur votre site, chaque fois que vos utilisateurs résolvent un captcha, les données de l’utilisateur sont renvoyées à Google. Google peut utiliser ces données pour améliorer ses services, par exemple en apprenant à la machine à classer les photographies de manière plus intelligente. Ces données peuvent également être sensibles en ce qui concerne la protection de la vie privée.
Hcaptcha est fourni par Intuitive Machine, qui est loin d’être un magnat des données et prétend protéger la vie privée des utilisateurs.
4. Pourquoi les sites Web appliquent-ils CAPTCHA
De nos jours, l’informatique est devenue omniprésente et les tâches et services informatisés sont répandus, de sorte que la sécurité a été plus importante. Le développement de CAPTCHA vise à s’assurer qu’ils traitent avec des humains dans des situations où l’interaction humaine est essentielle à la sécurité, par exemple, se connecter à un site Web ou payer sur Internet.
CAPTCHA bloque également les spammeurs et les robots qui tentent de collecter automatiquement des données en ligne, tentent de s’inscrire automatiquement ou d’utiliser des sites Web, des blogs ou des forums. Il protège les sites Web contre le dépassement par le spam, les inscriptions frauduleuses et d’autres comportements illégaux.
5. Comment contourner CAPTCHA pour le web scraping
CAPTCHA peut facilement décomposer les robots que vous avez configurés une fois qu’il apparaît dans le processus d’extraction, il est donc essentiel de le gérer pour le Web scraping.
La meilleure façon de gérer un CAPTCHA est de faire de votre mieux pour éviter de le rencontrer :). N’essayez jamais de trop gratter un site Web, mais agissez plutôt comme un humain.
Si vous utilisez un outil de web scraping nocode comme Octoparse, vous avez dans le plupart de cas la flexibilité de configurer un web scraper pour qu’il ressemble au plus grand degré comme un humain. Par exemple, faire très attention au délai de scraping, à la fréquence de scraping, utiliser des proxies présidentiels, appliquer des modes d’extraction de données différents, etc. (Nous avons un autre article expliquant comment éviter les blocages lors du grattage et vous pouvez le vérifier pour voir comment créer un web scraper en 5 minutes avec Octoparse sans être bloqué.) Mais il y a encore beaucoup de CAPTCHA qui ne peuvent être évités comme le CAPTCHA sur la page de connexion. Dans Octoparse, vous pouvez résoudre manuellement le CAPTCHA aussi facilement que ce que vous faites normalement lorsque vous naviguez sur un site. Au cas où un captcha est inévitable, Octoparse propose également des solutions de CAPTCHAs pour les hCaptcha, les reCaptcha et les Captcha image.
Pour les personnes qui codent leurs propres scrapers, il existe de nombreux solveurs CAPTCHA qui peuvent être intégrés dans leur système de scarping. Par exemple, Death by CAPTCHA et Bypass CAPTCHA permettent aux utilisateurs de se connecter au service via l’API pour réaliser la résolution automatique de CAPTCHA pendant le processus de scraping. Ces outils de résolution CAPTCHA peuvent traiter le texte normal CAPTCHA et même reCAPTCHA. Si nécessaire, 2CAPTCHA est un merveilleux fournisseur de services pour vous aider à résoudre le problème.
En conclusion
CAPTCHA peut être un problème épineux pour le web scraping. Mais ne vous inquiètez pas. Avec chaque génération de CAPTCHA, il y a chaque génération de bots. CAPTCHA est devenu vaincu avec la montée en puissance des outils de scraping et des solveurs CAPTCHA. Vous pouvez profiter du Web scraping sans entrave à l’aide de ces outils.



