Avec le développement de votre business, faire passer l’extraction de données à un niveau supérieur et commencer à extraire les données des sites web à grande échelle deviennent une tendance. L’extraction d’une grande quantité de données n’est pas une tâche facile. Vous pouvez rencontrer quelques difficultés comme le blocage, le surcharge de l’espace de stockage, etc.
Le scraping basé sur cloud semble une solution idéale pour répondre à ces défis. Voyons de plus près comment le cloud scraping permet d’extraire un nombre volumineux de données rapidement et automatiquement.
Obstacles dans le scraping web à grande échelle
Structure dynamique des sites web
Il est facile de gratter des pages web en HTML. Cependant, de nombreux sites Web s’appuient de plus en plus fortement sur les techniques Javascript/Ajax pour le chargement dynamique du contenu, rendant le scraping plus difficile ou complexe.
Technologies anti-scraping
Pour s’éloigner des spam, des sites web appliquent des dispositifs anti-scraping tels que Captchas ou placent toutes les données derrière une connexion. Et tout cela devient un grand défi pour un scraper web. Comme ces technologies anti-scraping appliquent des algorithmes de codage complexes, il faut beaucoup d’efforts pour trouver une solution technique permettant de les contourner. On doit même parfois avoir recours à un logiciel tiers comme 2Captcha pour résoudre ces technologies anti-scraping.
Chargement lent de conteu
Plus le nombre de pages Web à parcourir est élevé, plus le processus d’extraction de données est long. Il est évident que le scraping à grande échelle consommera beaucoup de ressources sur une machine locale. Une surcharge de la machine locale peut entraîner une panne.
Espace insuffisant pour le stockage de données
Puisque on doit extraire des données depuis des sites web à grande échelle, cela nécessite une solide infrastructure d’entreposage de données pour pouvoir les stocker en toute sécurité. Mais la maintenance d’une telle base de données demande beaucoup d’argent et de temps.
Face à tous ces défis, on se dépêche de trouver une solution capable de faire la scraping à grande échelle plus facilement, plus rapidement, à un coût plus bas, avec davantage de précision.
Aujourd’hui, je vous propose le cloud scraping d’Octoparse.
Bien qu’il s’agisse là de défis courants dans l’extraction à grande échelle, Octoparse a déjà aidé de nombreuses entreprises à résoudre ces problèmes.
Meilleure solution – cloud scraping d’Octoparse
Octoparse est un outil de web scraping surtout destiné aux non-codeurs et il propose également un service Cloud qui est surtout adapté pour un grand projet de scraping de données.
Octoparse Cloud utilise un système distribué et permet un traitement multithread, ce qui signifie que l’ensemble de données cibles sont crawlés simultanément sur 6 machines virtuelles ou plus. Le cloud scraping est beaucoup plus efficace par rapport à une extraction locale. Mais attention, le service Cloud est limité à un plan premium et vous pouvez vous abonner à un essai gratuit de 14 jours tout d’abord.
Les utilisateurs peuvent facilement lancer une extraction de données sur le cloud, stocker les données dans le cloud, etc sur Octoparse. L’extraction Cloud vous permet d’extraire les données de vos sites Web cibles 24 heures sur 24, 7 jours sur 7, et de les transférer dans votre base de données, de manière totalement automatique. Et quel est l’avantage ? Vous n’avez pas besoin de rester assis devant votre ordinateur et d’attendre que la tâche soit accomplie.
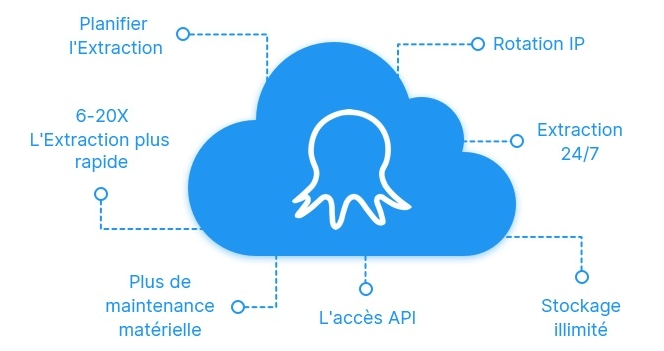
1. Extraire les données plus rapidement
Dans Octoparse, nous appelons un projet de scraping “task” (tâche). Lextraction cloud est jusqu’à 6 à 20 fois plus vite qu’une exécution locale de la tâche de scraping.
Le scraping cloud d’Octoparse fonctionne de la sorte : lorsqu’une tâche est configurée pour s’exécuter sur le cloud, Octoparse l’envoie à plusieurs serveurs cloud qui va exécuter le scraping simultanément. Par exemple, il y a un projet qui consiste à extraire des informations sur 10 oreillers différents sur Amazon. Au lieu de parcourir les 10 oreillers un par un, Octoparse envoie la tâche à 10 serveurs Cloud qui vont chacun extraire les données d’un des 10 oreillers. A la fin, vous obtiendrez les données en 1/10e du temps par rapport à l’extraction locale.
Il s’agit apparemment d’une explication très simple de l’algorithme Octoparse, mais vous pouvez déjà comprendre l’idée.
2. Scraper plus de sites web simultanément
Le scraping cloud permet de scraper jusqu’à 20 sites Web simultanément. A l’instar du principe mentionné, chaque site web est crawlé sur un seul serveur cloud qui renvoie ensuite les données extraites sur votre compte.
Vous pouvez définir la priorité des différentes tâches pour vous assurer que les sites web seront scrapés dans l’ordre souhaité.
3. Stockage illimité de données sur le cloud
Lors de l’extraction de données dans le nuage, Octoparse supprime les données dupliquées et stocke les données néttoyées dans le cloud, de sorte que vous pouvez facilement accéder aux données à tout moment, où que vous soyez. Ce qui semble plus fascinant est qu’il n’y a aucune limite à la quantité de données que vous pouvez stocker.
Vous pouvez même intégrez Octoparse à votre propre programme ou base de données via une API pour gérer vos tâches et vos données.
4. Planifier des exécutions pour l’extraction régulière de données
Si vous avez besoin de flux de données réguliers provenant de sites Web, cette fonction est faite pour vous. Avec Octoparse, vous pouvez facilement définir des configurations de vos tâches pour qu’elles soient exécutées selon un calendrier, quotidiennement, hebdomadairement, mensuellement ou même à un moment précis de la journée. Une fois la configuration terminée, cliquez sur “Save and Start”. La tâche s’exécutera comme prévu.
Cette fonctionnalité est surtout populaire parmi ceux qui ont besoin de surveiller les concurrents ou suivre les newletters/les blogs des concurrents. Beaucoup sont également ceux qui en profitent pour alimenter leur propre site web, comme un comparateur de prix ou un aggrégateur de données d’emplois.
5. Moins de blocage
L’extraction Cloud réduit le risque d’être bloqué. Vous pouvez utiliser des proxies IP, changer d’agent utilisateur, effacer les cookies, ajuster la vitesse d’extraction, etc pour éviter d’être capturé.
Dans notre société, les données constituent déjà un guide critique pour faire des décisions commerciales ou pour décider des pratiques ou stratégies importantes. Notre intention consiste toujours à offrir un bon outil pour collecter les données à grande échelle qui apporteront une croissance à votre business.