Dans l’industrie d’e-commerce, un océan de données sont générées autour des ventes et des produits. Quand les données sont le premier matériel pour mener des analyses et prendre des décisions, c’est surtout le cas pour les e-commerçants qui se lancent dans une industrie qui change d’une vitesse vertigineuse. Cet article va cibler une solution simple pour extraire à grande échelle les données de sites e-commerce en soulevant tous les défis du data scraping au milieu de l’e-commerce.
Les caractéristiques des données de sites d’e-commerce
L’e-commerce est une industrie qui se déploie totalement sur Internet, définissant déjà les principales caractéristiques des données de cette industrie :
- Les données sont d’un volume terrible
L’e-commerce couvre tous les aspects de nos vies, allant des petites affaires quotidiennes aux voitures en passant par des services virtuels. On compte des millions d’acteurs dans le monde entier : certains établissent des boutiques électroniques sur de grandes plateformes comme Amazon ou Shopee, d’autres vendent des produits sur leurs propres sites indépendants. Selon les statistiques, environ 2,14 milliards de personnes dans le monde ont effectué des achats en ligne en 2021. Cependant, il convient de noter que ce chiffre est en constante évolution et contine d’augmenter. Autour des produits et des ventes se génèrent des données qui sont les informations des produits, les tendances visibles, les prix changeants, les données sur le stockage, les avis clients, etc.
- Les données sont d’une grande variété
Ces données comprennent des listes de produits, des images, des liens, des chiffres, des informations détaillées sur les produits, des avis clients, etc. En outre, ces données sont stockées d’une façon différente : se trouver dans un menu déroulant, exiger la pagination, se charger avec ajax, se cacher derrière une connexion, s’étendre sur la page de résultats et la page de détails, etc.
Le secteur d’e-commerce naît avec l’Internet et est basé sur l’Internet. Quand le dernier a pour mot-clé les données, les données jouent également un rôle crucial dans la réussite d’une entreprise de commerce électronique. Avant de décider son cible, on mène des analyses du marché et des concurrents pour prendre des décisions sur les stratégies ; et puis utiliser les données de ventes dans la fin d’optimiser le prix, d’améliorer des campaignes de promotion, de comprendre les avis clients pour adapter le mieux le prix et les produits aux besoins et attentes des consommateurs.
A travers les trois principales caractéristiques des données d’e-commerce, on comprend d’une part le besoin brûlant de la collecte de données, et d’une autre part, les défis se révèlent pour extraire les données d’un tel nombre et d’une telle variété.
Les défis du data scraping au milieu de l’e-commerce
Le web scraping de l’e-commerce est loin d’être une chose facile. Je vais faire un petit résumé sur les défis que vous rencontriez probablement dans votre projet de scraping de données de l’e-commerce.
- Scraper des sites d’une structure différente
Si vous ciblez les produits vendus par vos concurrents, il est probable que vous devriez scraper non seulement les données des grandes plateformes comme Amazon ou Cdiscount, mais également des sites indépendants des marques et des fabricateurs. Les sites différents emploient une structure différentes et donc, il vous faut créer un web scraper pour chacun d’entre eux.
- Extraire les données de tout genre
Les sites d’e-commerce appliquent des genres de données variés : image, tableaux, texte, url, dossier pour bien décrire un produit. Les données peuvent se trouver dans un menu déroulant, derrière un hover, après un ajax, etc. Donc notre scraper doit être assez polyvalant.
- Régler la pagination pour extraire les données depuis autant de pages possibles
Le nombre de produits vendus sur Amazon est déjà difficile à estimer, plus de353 millions vendus sur sa marketplace selon plusieurs sources. La pagination est à régler pour extraire le plus d’informations possbiles.
- Résoudre des captchas et contourner le blocage de scraping
Les captchas constituent une technique anti-scraping largement utilisée par les sites, et parfois des requêtes trop fréquentes risquent de conduire au blocage total. Dans ce cas, il est important de faire entrer des services tiers de solution de captcha et n’oubliez pas d’ajuster la vitesse de scraping ou d’utiliser des proxies IP pour éviter le blocage.
- Accélérer le processus d’extraction et d’exportation de données
Dans l’e-commerce, s’il y a un besoin, il s’agit souvent d’une demande des millions de données, faisant l’accélération du processus d’extraction et d’exportation de données beaucoup plus critique. Certains outils de web scraping proposent le service Cloud permettant d’exécuter des tâches avec plusieurs processus cloud simultanés. S’agissant de l’exportation de données, API ou exportation automatique ne manquent pas d’être une solution populaire.
L’e-commerce est une industrie qui change rapidement et on a des exigences plus élevées en matière de temps réel. Pour ce faire, on combine souvent l’extraction programmée à l’exportation programmée pour que l’extraction et l’exportation commencent chaque trois heures ou selon ce que vous définissez.
Les sites d’e-commerce sont surtout dynamiques et complexes par rapport à d’autres sites Web. Les défis mentionnés ci-dessus ne sont pas encore complets. Si vous rencontrez encore d’autres problèmes difficiles à régler, pourquoi pas rejoindre notre groupe Discord sur le web scraping pour commencer des discussions. Voilà le lien d’invitation :
https://discord.gg/h7PDu7ns
Moyen simple d’extraction de données de sites e-commerce
L’e-commerce data scraping, c’est pas du tout un travail facile. Mais beaucoup de fournisseurs de logiciels travaillent toujours dûr pour le faciliter. Après des recherches, je considère comme le moyen le plus simple d’extraction de données de sites e-commerce profiter d’une plateforme tout-en-un, par exemple, Octoparse. Il est loin de dire que c’est un outil destiné au web scraping d’e-commerce mais le logiciel convient bel et bien les besoins spécifiques du secteur en relevant tous les défis.
Les avantages d’Octoparse
Premièrement, il peut être utilisé pour extraire les données depuis presque tous les sites Web. L’outil propose deux modes d’extraction de données : le mode de template et le mode de personnalisation, assurant la flexibilité. Donc, les utilisateurs peuvent entrer les URLs de n’importe quels sites et faire des pointer-cliquers pour extraire n’importe quels champs de données qui les intéressent, quels que soient leur genre de chargement : pagination, ajax, derrière connexion, etc. En outre, la détection automatique s’applique toujours pour réduire le travail.
Deuxièmement, Octoparse apporte diverses solutions aux techniques de anti-scraping pour assurer la complétitude des données. Le service de résolution de Captchas est disponible, les proxies IP résidentiels intégrés et la rotation de IP permettent de réduire au minimum le risque d’être bloqué. En outre, Octoparse permet de définir le délai de temps entre deux actions pour éviter d’être détecté par le site cible.
Troisièmement, l’extraction de données peut être accélérée si on exécute les tâches sur plusieurs processus Cloud simultanément. Par exemple, ceux qui s’abonnent au plan Standard peuvent utiliser jusque 6 processus Cloud simultanés et les utilisateurs Professionnels peuvent utiliser 20 processus. Sur Cloud, l’extraction s’exécute 24 heures sur 7 jours, que vous allumez ou pas votre ordinateur. Quand l’extraction est finie, on peut programmer ou automatiser l’exportation de données vers une base de données, ou d’autres applications tierces via API.
Exemples d’extraire des données de sites e-commerce
Extraire les informations sur les produits
Étape 1 : Téléchargez, installez et créez un compte gratuitement dans Octoparse. Ensuite, copiez l’URL de la page produit Amazon que vous souhaitez scraper et collez-la dans la page d’accueil d’Octoparse, cliquez sur “Auto-detect Webpage data” pour lancer la détection automatique.
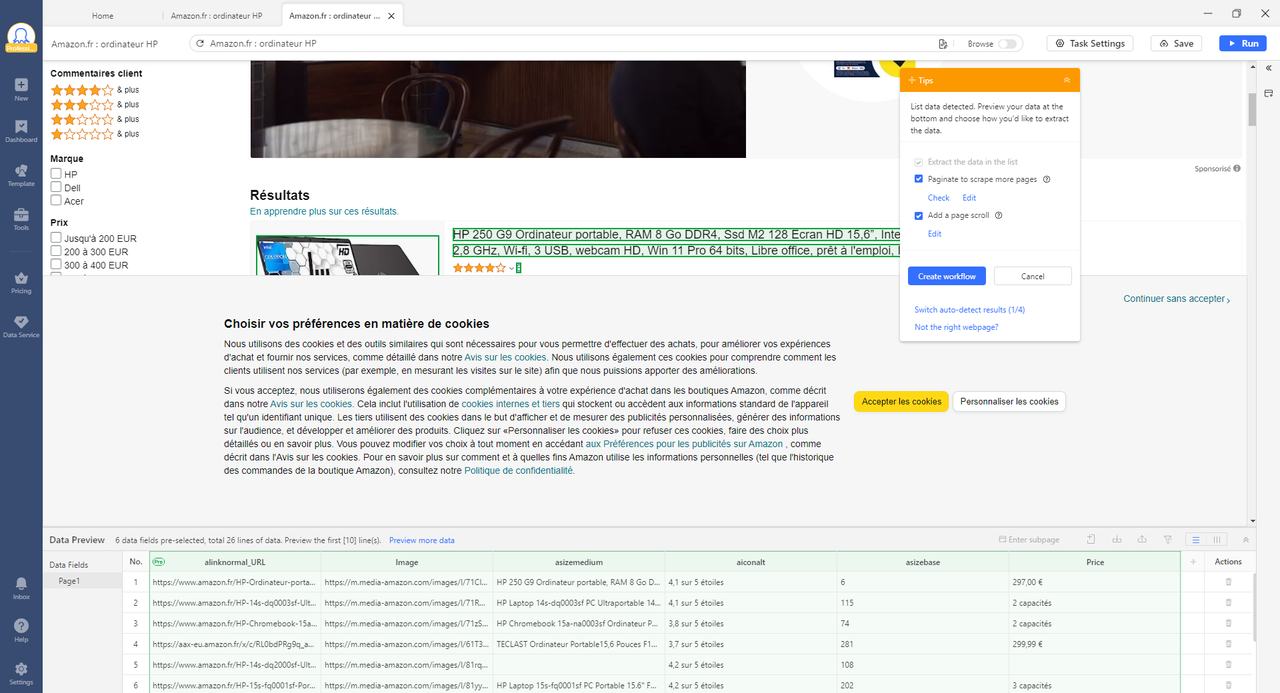
Étape 2 : Cliquer sur le titre du premier produit et puis sélectionner “Click Element” dans le panneau de conseils.
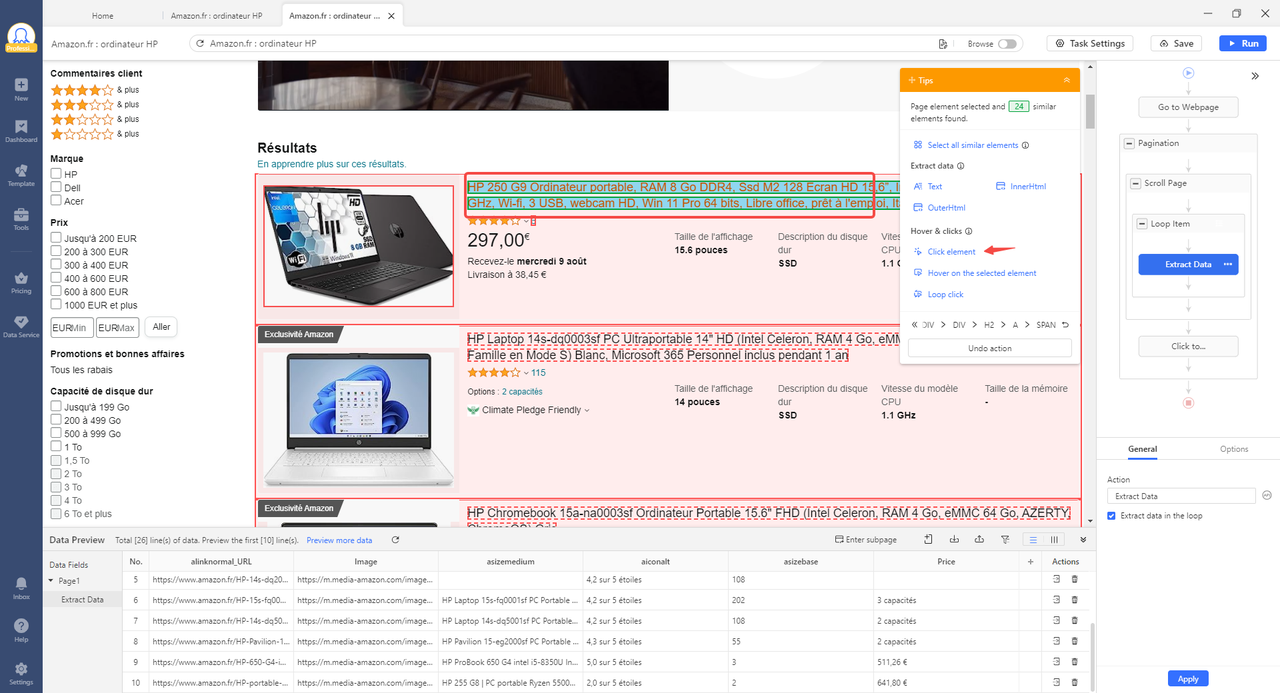
Étape 3 : Cliquer sur les champs de données désirés et puis sélectionner “Text”. Par exemple, cliquer sur l’élément qui vous intéresse et puis sélectionner “Extract data” >>”Text”. Répétez le processus si vous avez à extraire plusieurs champs de données. Dans notre exemple, je récupère le titre, l’URL de la page détaillée, l’URL de l’image depuis la page de résultats, le stockage, les évaluations depuis la page de détails.
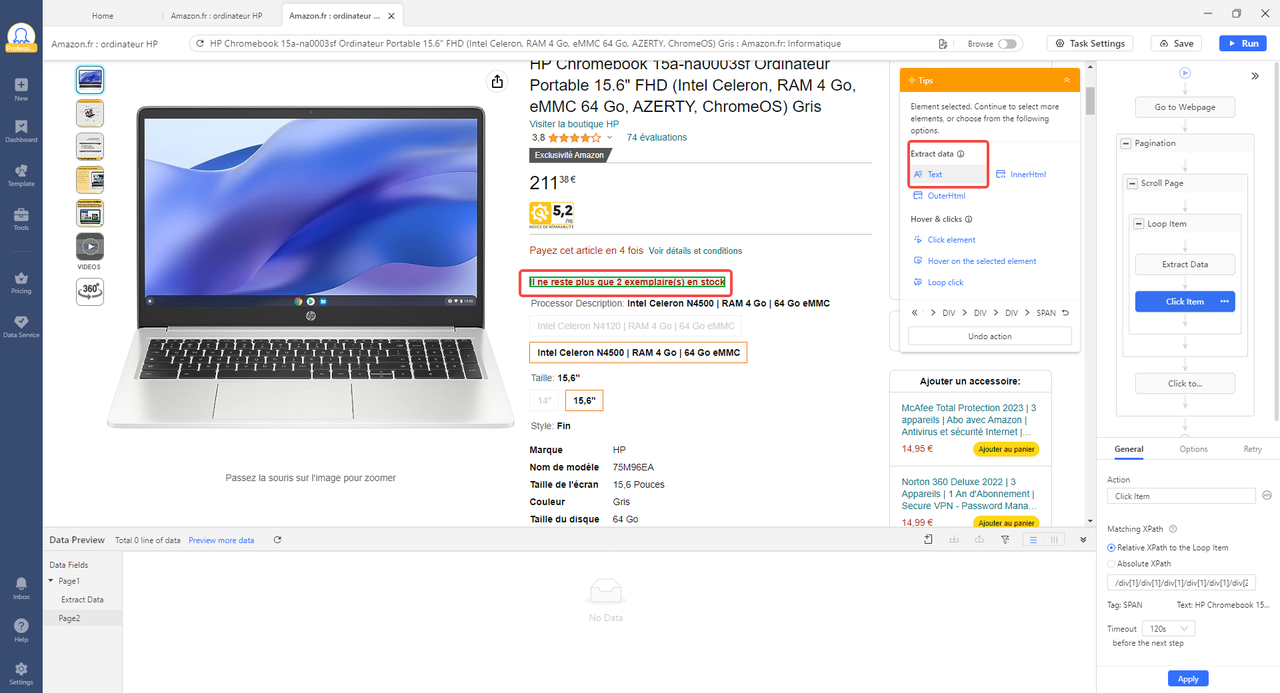
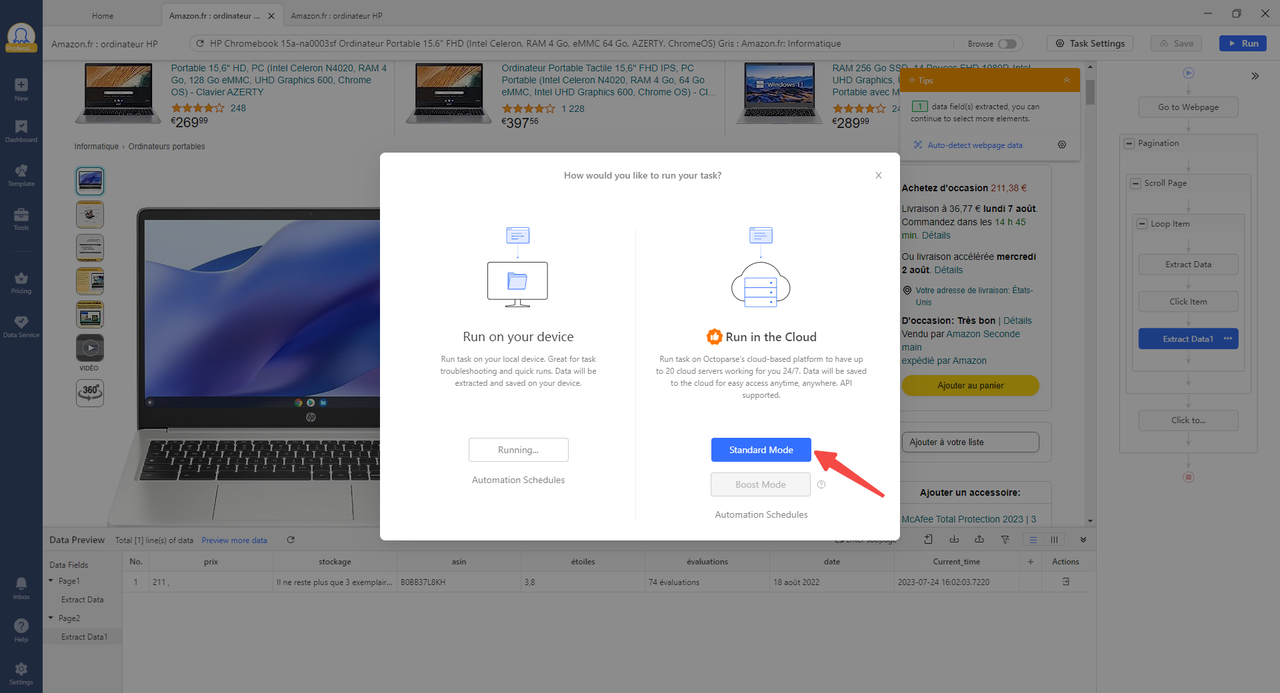
Étape 4 : Lancer la tâche de scraping localement ou sur Cloud
J’aimerais lancer la tâche de web scraping sur Cloud parce que je n’ai plus besoin de veiller sur son exécution. Mon projet va être divisé en plusieurs sous-tâches s’il le peut, accélérant ainsi grandement l’extraction de données. S’il est nécessaire, les proxies IP résidentiels peuvent être ajoutés au projet pour éviter d’être bloqué.
Étape 5 : Exporter les données
Les données peuvent être exportées vers des fichiers locaux ou vers une base de données via API. La dernièr version du logiciel permet de programmer et d’automatiser l’exportation de données.
Extraire les prix des produits
Étape 1 : Créer une boucle. Cliquer sur le premier produit et puis le deuxième, jusque là, Octoparse va détecter les éléments d’une structure similaire et les surligner en vert. Cliquer sur “Text” pour créer une boucle.
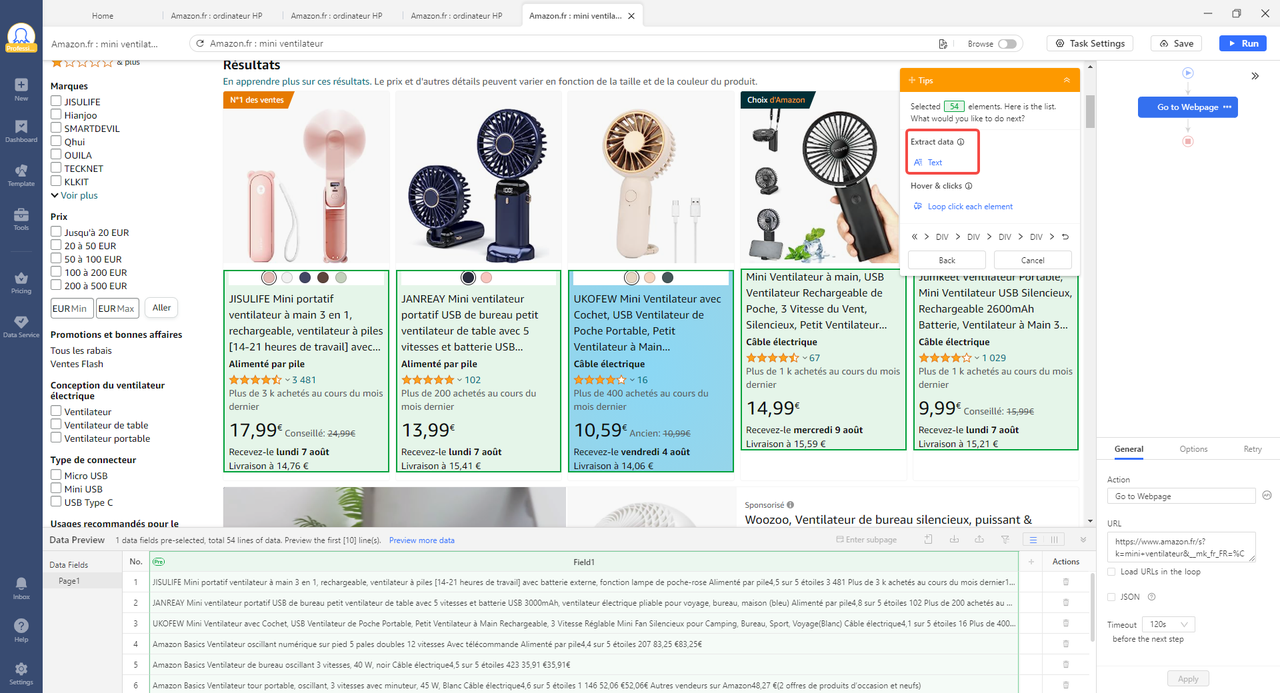
Étape 2 : Cliquer sur le titre et les chiffres qui disent le prix et sélectionner encore une fois “Text”. Ainsi, on obtenira le titre du produit et le prix correspondant. Il est noter d’ajouter le temps d’extraction ici.
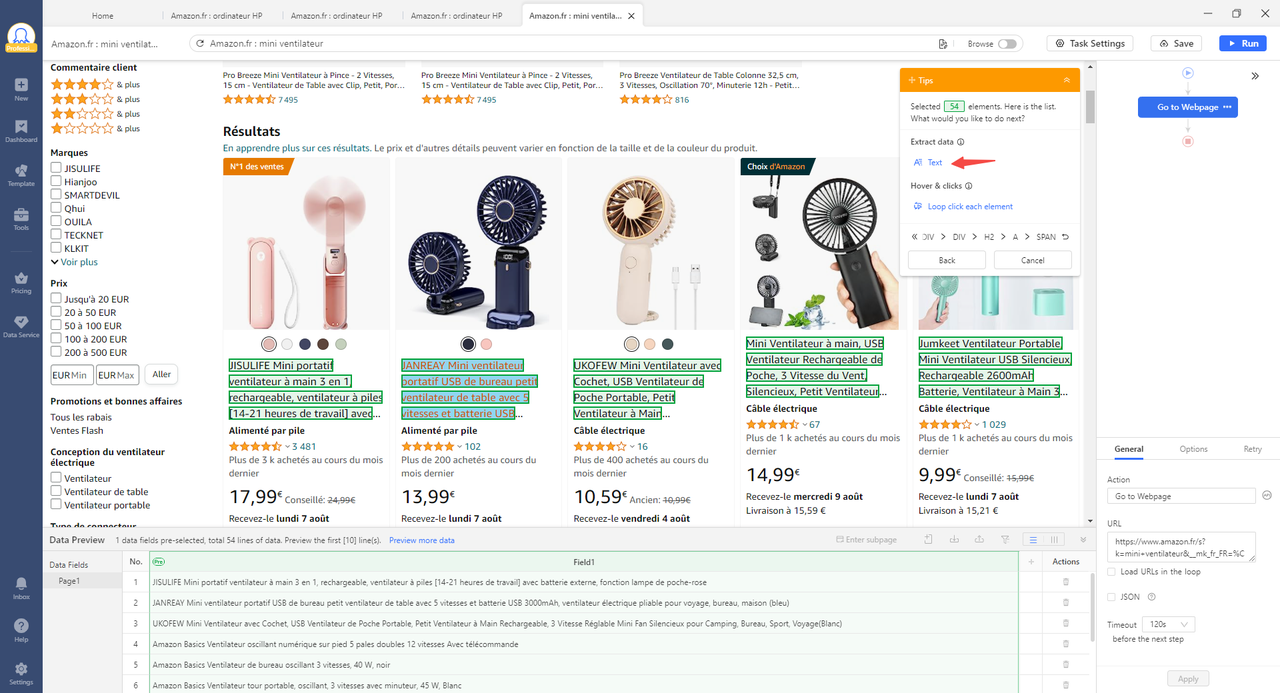
Étape 3 : Commencer le web scraping et puis exporter les données.
Extraire les avis clients laissés par les acheteurs
Étape 1 : Entrer l’URL cible. URL d’exemple.
Étape 2 : Lancer la détection automatique. Vous verrez que le robot a déjà réussi à configurer la pagination pour vous et à détecter exactement les champs de données qu’on veut. Renommer les champs de données et supprimer ceux peu importantes.
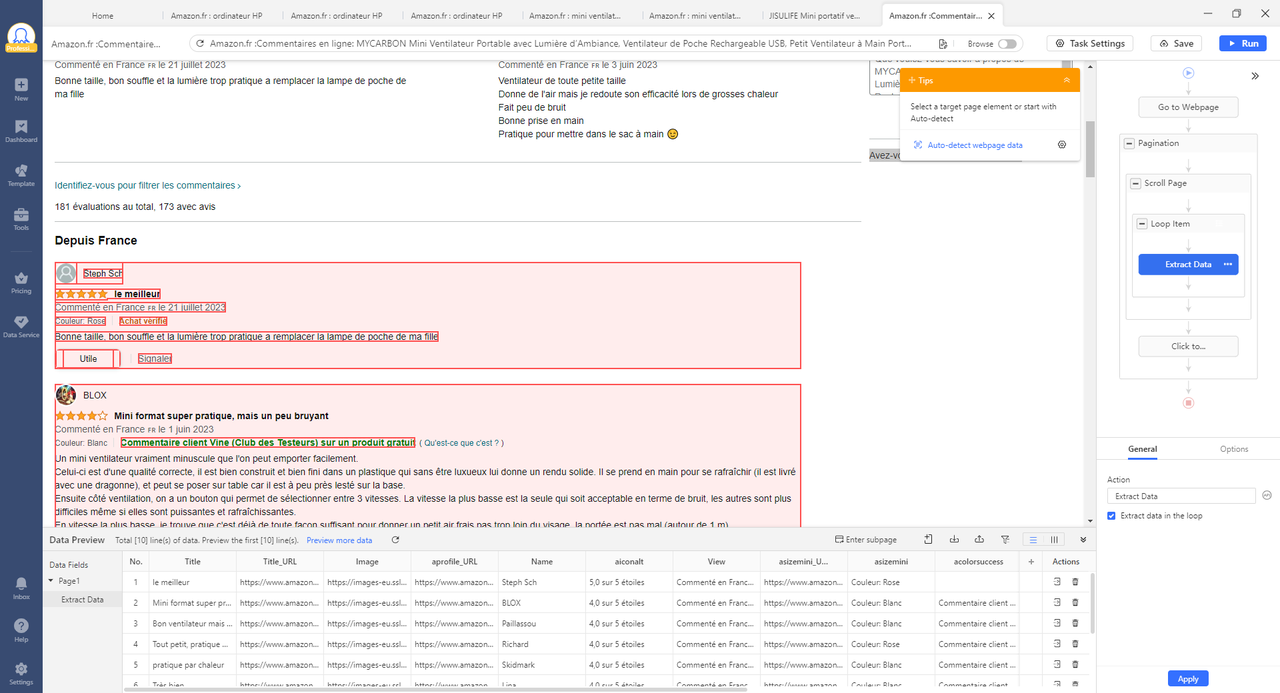
Étape 3 : Commencer le web scraping
En conclusion
Le web scraping de sites d’e-commerce a ses propres défis et caractéritiques vu que les données de l’industrie font preuve des particularités. La vitesse, la complétitude de données, le blocage, et beaucoup d’autres facteurs doivent être prises en considération et le meilleur choix est de choisir une plateforme tout-en-un pour le data scraping en e-commerce. Octoparse ne manque pas d’être une solution idéale pour extraire les données des produits, ou les avis clients.



