Amazon réunit un trafic mensuel estimé à 2.5 milliards de visites qui génèrent un océan de données de valeur. Elles sont les informations des produits, les commentaires laissés par les acheteurs, les détails des vendeurs, etc. Il compte des centaines de possibilités de profiter de ces données, comme surveillance de prix, veille concurrentielle, VOC, etc selon votre objectif. Un problème important : comment extraire les données d’e-commerce à grande échelle ?
Dans cet article, on verra des Amazon scrapers qui sont développés dans la fin de faciliter l’extraction de données d’Amazon, vous permettant d’extraire les données sur les pages de résultats de recherches, sur des pages de détails, et extraire les avis clients.
La liste comprend d’une part des outils d’extension plus légers mais relativement limité, d’autre part, des logiciels de web scraping multifonctionnels plus puissants qui requièrent une installation. En plus d’une énumération des outils, une comparaison y est ajoutée selon trois dimensions : 1) le niveau d’automatisation ; 2) la convivialité de l’interface utilisateur ; 3) le niveau d’utilisation gratuite.
Logiciels de web scraping
Au cours de l’extraction de données, vous risquez de rencontrer des problèmes ennuyeux qui vous empêchent d’obtenir les données – interdiction d’IP, captcha, pagination, données sous différentes structures, etc. Des logiciels d’extraction de données assez puissants donnent toujours des solutions. En tant que logiciels de bureau, ils proposent plusieurs fonctionnalités pour aider les utilisateurs à obtenir les données les plus complètes, structurées, exactes possible depuis le plus de sites possible. Par exemple, Octoparse ose dire que l’outil est capable de régler 98% des sites Web.
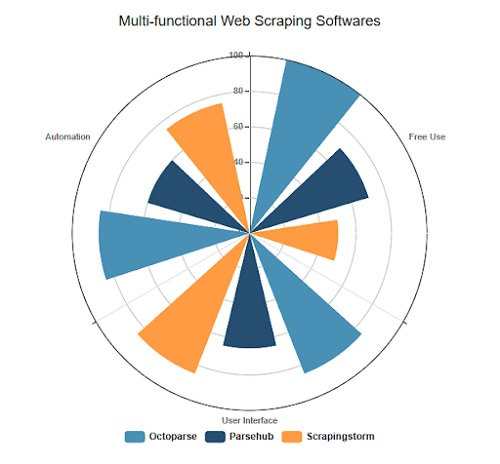
Ici, on fait entrer dans la liste trois outils : Octoparse, Parsehub, ScrapeStorm.
Voyons d’abord un diogramme de comparaison.
�
Octoparse
Octoparse est un des logiciels les plus populaires d’extraction de données. En tant que outil de non-codage, il a pour but de rendre le web scraping accessible à tous pour que tout le monde, surtout ceux qui n’ont pas de connaissance technique mais ont besoin d’un grand nombre de données, puissent scraper les données sans codage.
C’est un outil facile à utiliser mais puissant dans l’extraction de données. Grâce à son interface “pointer-cliquer”, les utilisateurs peuvent extraire les données en trois étapes et transformer les pages Web en feuilles de calcul structurées en quelques clics. Dans la fin de faciliter l’utilisation, Octoparse propose des modèles de web scraping prêts à l’emploi. Et avec la fonction de détection automatique, les utilisateurs peuvent régler facilement les sites web que les modèles ne couvrent pas encore.
https://www.octoparse.fr/template/amazon-fr-listing-scraper
Amazon se classe en troisième position sur la liste de 10 sites les plus scrapés en France. De nombreuses modèles de web scraping sont créées pour scraper les pages de résultats, les pages de détails des produits, les avis laissés par les acheteurs. Pour l’utiliser, trois étapes sont suffisantes : trouver le modèle approprié – cliquer sur “Essayez-le” et entrer les mots-clé ou les URLs selon les instructions – lancer la tâche de scraping et puis exporter les données récupérées.

Tutoriels conseillés :
Amazon scraping sans code pour obtenir les données de produits
Comment extraire les aivs et les évaluations clients Amazon pour l’analyse des sentiments ?
Price Scraping : Outils gratuits pour scraper les données sur les prix
ScrapeStorm
ScrapeStorm est un outil de scraping web visuel alimenté par l’IA. Son mode intelligent fonctionne de manière similaire à l’auto-détection d’Octoparse, identifiant les données avec peu d’opérations manuelles. Il vous suffit donc de cliquer et de saisir l’URL de la page d’Amazon que vous souhaitez extraire. D’une manière générale, l’interface utilisateur de l’application est semblable à celle d’un navigateur et confortable à utiliser.
ScrapeStorm offre un quota gratuit de 100 lignes de données par jour et une seule exécution simultanée est autorisée. Les données prennent de la valeur lorsque vous en avez suffisamment pour les analyser, vous devez donc penser à mettre à niveau votre service si vous choisissez cet outil. Passez à la version professionnelle pour obtenir 10 000 lignes de données par jour.

ParseHub
Parsehun est un autre scraper web disponible en téléchargement direct. Comme la plupart des outils de scraping ci-dessus, il prend en charge la construction de crawlers en mode “clic et sélection” et l’exportation de données dans des feuilles de calcul structurées.
Pour les scrapers Amazon, Parsehub ne prend pas en charge l’auto-détection et ne propose pas de modèles Amazon. Cependant, si vous avez déjà utilisé un outil de scraping pour créer des crawlers personnalisés, vous pouvez essayer. Dans Parsehub,vous exécuter avec la rotation des IP et la programmation si vous partez d’un plan standard. Les utilisateurs du plan gratuit recevront 200 pages par exécution. N’oubliez pas de sauvegarder vos données (conservation des données pendant 14 jours).
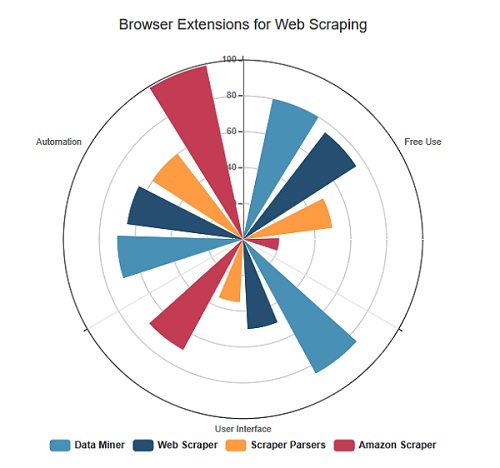
Extensions de navigateur
Par rapport aux logiciels d’extraction de données, l’avantage des extensions de navigateur consiste à son légèreté. En les ajoutant sur votre navigateur, vous pouvez effectuer l’extraction de données plus directement. Avec des fonctions plutôt basiques, ces options sont adaptées au scraping occasionnel ou aux petites entreprises qui ont besoin d’informations dans une structure simple et en petites quantités.
Webscraper
Comme ce que indique son slogan “rendre le web scraping facile et accessible à tout le monde”, Webscraper.io est d’une interface pointer-cliquer, ne nécessitant aucune connaissance de codage. Il vous permet d’extraire presque toutes les données : celles des catégories, sub-catégories, produits, détails et vous pouvez les exporter vers XML, XLSX, JSON ou via API. Mais en tant que petit outil, des fonctions importantes manquent. Par exemple, la détection automatique, l’extraction de données de la page actuelle, le téléchargement de fichiers, les modèles prêts-à-l’emploi, etc.
Data Miner
Data Miner est un outil d’extension qui fonctionne sur Google Chrome et Microsoft Edge. Il vous aide à extraire des données de pages Web pour les transférer dans un fichier CSV ou une feuille de calcul Excel. Un certain nombre de recettes personnalisées sont disponibles pour scraper les données d’amazon. Si les recettes proposées correspondent exactement à vos besoins, il s’agit d’un outil pratique qui vous permettra de scraper des données d’Amazon en quelques clics.
Data Miner possède une interface conviviale et des fonctions de base en matière de scraping web. Il est plus recommandé pour les petites entreprises ou pour une utilisation occasionnelle.
Il y a une limite de pages (500/mois) pour le plan gratuit avec Data Miner. Si vous avez besoin de scraper plus, des plans professionnels et d’autres plans payants sont disponibles.
Scraper Parsers
Scraper Pasers est une extension de navigateur permettant d’extraire des données non structurées et de les visualiser sans code. Les données extraites peuvent être visualisées sur le site ou téléchargées sous différentes formes (XLSX, XLS, XML, CSV). Avec les données extraites, les chiffres peuvent être affichés dans des graphiques en conséquence.
L’interface utilisateur de Parsers est un panneau que vous pouvez faire glisser et sélectionner par des clics sur le navigateur et il supporte également le scraping programmé. Cependant, elle ne semble pas assez stable et se bloque facilement. Pour un visiteur, la limite d’utilisation est de 600 pages par site. Vous pouvez en obtenir 590 de plus si vous vous inscrivez.
Amazon Scraper – Version d’essai
Amazon scraper est accessible sur la boutique d’extension de Chrome. Il permet de récupérer le prix, les frais d’expédition, l’en-tête du produit, les informations sur le produit, les images du produit, l’ASIN de la page de recherche Amazon.
Aller sur le site web d’Amazon et faire une recherche. Lorsque vous vous trouvez sur la page de recherche contenant les résultats que vous souhaitez extraire, cliquez avec le bouton droit de la souris et choisissez l’option “Extraire les données de cette page”. Les informations seront extraites et enregistrées dans un fichier CSV.
Cette version d’essai ne peut télécharger que 2 pages de n’importe quelle requête de recherche. Vous devez acheter la version complète pour télécharger un nombre illimité de pages et bénéficier d’un an de support gratuit.
Plus que des outils
Les outils sont créés pour faciliter l’extraction de données, permettant de réaliser des opérations compliquées en quelques clics sur une série de boutons.
Cependant, il est également fréquent que les utilisateurs rencontrent des erreurs inattendues et la situation évolue constamment sur les différents sites. Vous pouvez aller un peu plus loin pour vous sortir d’un tel dilemme – apprendre un peu de html et de Xpath. Il n’est pas nécessaire de devenir un codeur, seulement de faire quelques pas pour mieux connaître l’outil.
Si l’outil n’est pas votre truc, et que vous cherchez un service de données pour votre projet, le service de données Octoparse est un bon choix. Nous travaillons ensemble pour comprendre vos besoins en matière de données et nous nous assurons de vous fournir ce que vous souhaitez. Contactez dès maintenant un expert en données d’Octoparse pour discuter de la manière dont les services de scraping web peuvent vous aider à maximiser vos efforts.




