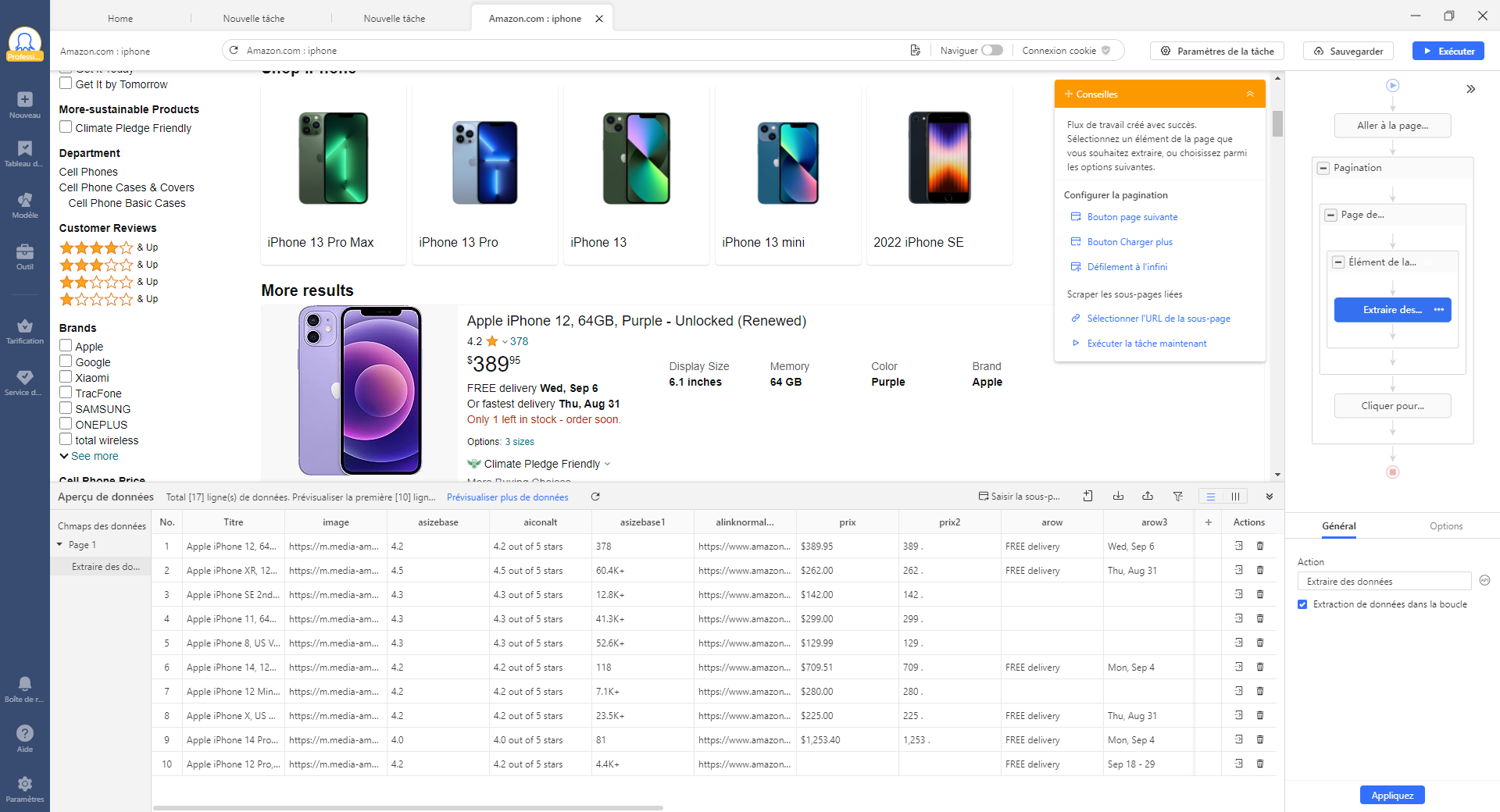
Le web scraping consiste à extraire des informations à partir du code HTML d’une page web. Un tel processus peut être réalisé avec des codes comme Python, PHP, C++ et bien d’autres. Cet article illustre comment un débutant peut construire un simple web crawler en PHP. Si vous envisagez d’apprendre PHP et de l’utiliser pour le web scraping, suivez les étapes ci-dessous.
Créer un Web Crawler en PhP
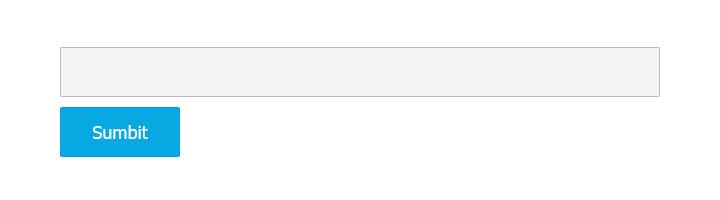
Étape 1 Ajoutez un champ de saisie et un bouton d’envoi à la page Web. Nous pouvons saisir l’adresse de la page Web dans le champ de saisie.
Étape 2 Les expressions régulières sont nécessaires pour extraire des données.
function preg_substr($start, $end, $str) // Regular expression
{
$temp =preg_split($start, $str);
$content = preg_split($end, $temp[1]);
return $content[0];
}
Étape 3 String Split est nécessaire lors de l’extraction de données.
function str_substr($start, $end, $str) // string split
{
$temp = explode($start, $str, 2);
$content = explode($end, $temp[1], 2);
return $content[0];
}
Étape 4 Ajouter une fonction pour sauvegarder le contenu de l’extraction :
function writelog($str)
{
@unlink(“log.txt”);
$open=fopen(“log.txt”,”a” );
fwrite($open,$str);
fclose($open);
}
Lorsque le contenu que nous avons extrait est incompatible avec ce qui s’affiche dans le navigateur, nous n’avons pas pu trouver les expressions régulières correctes. Ici, nous pouvons ouvrir le fichier .txt enregistré pour trouver la chaîne correcte.
function writelog($str)
{
@unlink(“log.txt”);
$open=fopen(“log.txt”,”a” );
fwrite($open,$str);
fclose($open);
}
Étape 5 Une fonction serait également nécessaire si vous avez besoin de prendre des photos.
function getImage($url, $filename=”, $dirName, $fileType, $type=0)
{
if($url == ”){return false;}
//get the default file name
$defaultFileName = basename($url);
//file type
$suffix = substr(strrchr($url,’.’), 1);
if(!in_array($suffix, $fileType)){
return false;
}
//set the file name
$filename = $filename == ” ? time().rand(0,9).’.’.$suffix : $defaultFileName;
//get remote file resource
if($type){
$ch = curl_init();
$timeout = 5;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file = curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$file = ob_get_contents();
ob_end_clean();
}
//set file path
$dirName = $dirName.’/’.date(‘Y’, time()).’/’.date(‘m’, time()).’/’.date(‘d’,time()).’/’;
if(!file_exists($dirName)){
mkdir($dirName, 0777, true);
}
//save file
$res = fopen($dirName.$filename,’a’);
fwrite($res,$file);
fclose($res);
return $dirName.$filename;
}
Étape 6 Nous allons écrire le code pour l’extraction. Prenons l’exemple d’une page web d’Amazon. Entrez un lien vers un produit.
if($_POST[‘URL’]){
//———————example——————-
$str = file_get_contents($_POST[‘URL’]);
$str = mb_convert_encoding($str, ‘utf-8’,’iso-8859-1’);
writelog($str);
//echo $str;
echo(‘Title:’ . Preg_substr(‘/<span id= “btAsinTitle”[^>}*>/’,’/<Vspan>/$str));
echo(‘<br/>’);
$imgurl=str_substr(‘var imageSrc = “’,’”’,$str);
echo ‘<img src=”’.getImage($imgurl,”,’img’ array(‘jpg’));
Ensuite, nous pouvons voir ce que nous extrayons. Voici la capture d’écran.

Web Crawling pour les non-codeurs
Comme indiqué précédemment, PHP n’est qu’un outil utilisé pour créer un robot d’exploration du Web. Les langages informatiques, comme Python et JavaScript, sont également de bons outils pour ceux qui les maîtrisent. Aujourd’hui, avec le développement de la technologie de web scraping, de plus en plus d’outils de web scraping, tels que Octoparse et Parsehub, apparaissent en multitude. Ils simplifient le processus de création d’un crawler web et même les non-codeurs peuvent facilement récupérer le plus de données possible avec ce genre d’outils de web scraping nocode.
Octoparse est l’un des meilleurs choix pour les non-codeurs. C’est facile à utiliser grâce à son interface pointer-cliquer. La détection automatique et les modèles prêts à emploi facilitent grandement l’extraction de données. Il vous faut entrer l’URL pour récolter les données sur des sites Web.