Si l’explosion de l’information nous offre la possibilité de choisir dans une grande variété de ressources, elle a également suscité des réflexions sur la manière d’éliminer le bruit et de se concentrer sur les sujets et les tendances spécifiques qui nous concernent. À cette fin, vous avez peut-être choisi de suivre vos blogs et les sites d’information favoris dans un lecteur RSS. Mais si vous rencontrez un site qui ne propose pas d’option RSS en texte intégral, que faites-vous ?
Dans cet article, nous vous présenterons quelques outils faciles à utiliser pour télécharger des blogs et des actualités (par exemple, un Scraper Medium). Nous vous guiderons dans la mise en place d’un scraper d’articles personnalisé capable de collecter rapidement, efficacement et de manière reproductible tous les articles dont vous avez besoin, quelle que soit leur longueur. Pas de RSS ? Pas de problème.
3 meilleurs logiciels destinées à la récupération d’articles
Il n’est pas facile d’identifier les meilleurs outils de scraping d’articles du marché parmi les nombreuses options disponibles. La chose importante à retenir est qu’il n’y a pas de meilleur choix unique, mais seulement le meilleur logiciel pour répondre à vos besoins en matière de données, qui dépendent de votre budget, de vos préférences en matière de visualisation(UI), des fréquences de scraping et de votre expérience.
La bonne nouvelle est que, que vous soyez un débutant cherchant à créer votre première tâche de scraping ou un chercheur de données chevronné cherchant à améliorer votre expérience du scraping, il existe certainement un outil pour vous.
Nous avons testé plus de dix outils de scraping web, et vous trouverez ci-dessous nos recommandations pour les 3 meilleurs du marché dans le domaine du scraping d’articles. Ces outils ont été sélectionnés non seulement en fonction de leurs fonctionnalités de scraping d’articles, mais aussi de leurs performances globales.
1. Octoparse
Octoparse est un outil de web scraping qui vous permet d’extraire des données de plusieurs sites Web sans utiliser le code. Il peut imiter le comportement de navigation humain et récupérer des articles et des publications de n’importe quel site Web en quelques minutes.

Interfaces Octoparse-Facile à démarrer
Il vous permet de naviguer sur les sites que vous préférez dans son navigateur intégré par des actions de type pointer-cliquer. Il est donc plus facile à utiliser que la plupart des outils de scraping.
Fonctions avancées
Octoparse offre de nombreuses fonctions puissantes pour vous aider à résoudre les problèmes liés au scrapping d’articles. Par exemple, si vous souhaitez récupérer des articles sur medium.Octoparse peut facilement résoudre des problèmes tels que les problèmes de connexion, la recherche des mots clés, et le défilement infini, etc.
Multiplateforme
En tant que logiciel gratuit basé sur le client, Octoparse est adapté à Windows et à Mac. Il est simple de télécharger et d’installer Octoparse sur le site officiel et d’essayer certains des modèles prêts à l’emploi pour l’extraction d’articles. Visitez son portail en libre-service pour obtenir des tutoriels si vous décidez de créer vous-même un crawler Web personnalisé.
Exécution en mode d’accélération et exécution planifiée
Octoparse est équipé d’un mode ” boost ” qui améliore considérablement la vitesse du scraping d’articles, tant sur les appareils locaux que dans le Cloud. Si vous souhaitez obtenir des articles ou des publications actualisés rapidement et facilement, Octoparse ne vous laissera pas tomber. Les crawlers d’Octoparse peuvent également être configurés de façon à être exécutés toutes les heures, tous les jours ou toutes les semaines afin que les articles soient livrés régulièrement, soit sur votre machine locale, soit en utilisant sa plateforme en cloud.
Services clientèle
L’équipe d’Octoparse offre également un support clientèle de qualité et s’engage à vous aider pour tous vos besoins en matière de données. Si le SaaS n’est pas votre solution, Octoparse propose également un service géré qui offre une solution complète pour tous vos besoins concernant les données.
2. WebHarvy
WebHarvy est un autre logiciel de scraping d’articles basé sur le client, mais il doit fonctionner avec le système d’exploitation Windows. Il peut être utilisé pour récupérer les annuaires d’articles et les publications de presse sur les sites de relations publiques(PR).
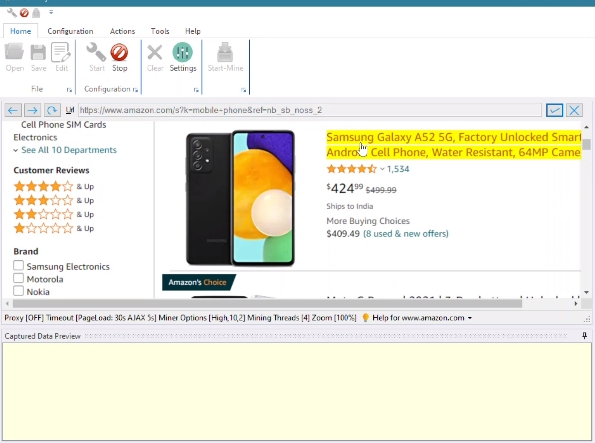

- Explication simple Vous pouvez consulter les vidéos explicatives sur le site officiel de WebHarvy qui expliquent comment créer une tâche pour extraire le titre, le nom de l’auteur, la date de publication, les mots clés et le corps du texte d’un article. Si vous êtes nouveau dans le domaine du web scraping, elles peuvent être une bonne base de départ.
- Version d’évaluation Il est fortement recommandé de télécharger et d’essayer leur version d’évaluation et de regarder les vidéos de démonstration de base pour commencer votre exploration des données. Il est très facile à utiliser et supporte également les proxies et le scraping planifié. S’il peut satisfaire vos besoins en termes de données, vous pouvez acheter une licence mono-utilisateur de WebHarvy au prix de 139 $ seulement. Vous bénéficiez d’un support gratuit et de mises à jour gratuites pendant 01 an.
3. ScrapeBox- Article Scraper Addon
ScrapeBox, l’un des outils de SEO les plus puissants et les plus populaires, propose un module complémentaire Article Scraper qui vous permet de collecter des milliers d’articles dans un certain nombre d’annuaires d’articles populaires.
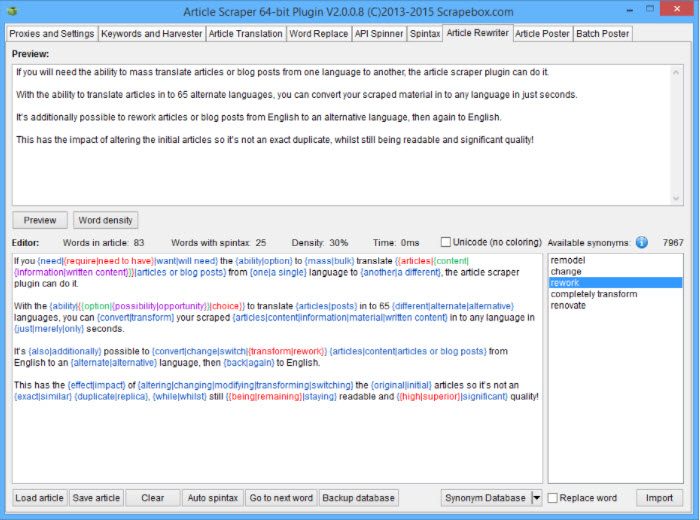
- Lightweight Add-on En tant qu’addon léger, le scrapeur d’articles de ScrapeBox présente les caractéristiques suivantes : (1) support des proxy, (2) multi-threading pour une récupération rapide des articles, (3) possibilité de préciser le nombre d’articles à scraper avant de s’arrêter, et (4) les articles peuvent être enregistrés au format ANSI, UTF-8 ou Unicode, ce qui permet de collecter des articles dans n’importe quelle langue.
- Filtre basé sur des mots-clés Il est également possible de supprimer automatiquement les liens et les adresses e-mail des articles, et d’enregistrer les articles dans des sous-dossiers basés sur des mots-clés. Ainsi, lorsque vous récupérez des articles pour de nombreux mots-clés en même temps, tous vos articles sont classés par catégorie.
- Advanced Plugin ScrapeBox propose également un plugin avancé de scraper d’articles qui permet de publier des articles, de faire évoluer des articles, de traduire des articles, et bien plus encore.
Étapes pour récupérer les articles Medium avec Octoparse
Pour mieux expliquer le fonctionnement d’un scraper d’articles, nous allons scraper les données d’articles de la Publications On Medium à l’aide d’Octoparse. Assurez-vous de télécharger la dernière version d’Octoparse avant de commencer.
Utilisez le lien ci-dessous pour suivre le processus : https://medium.com/tag/publications-on-medium
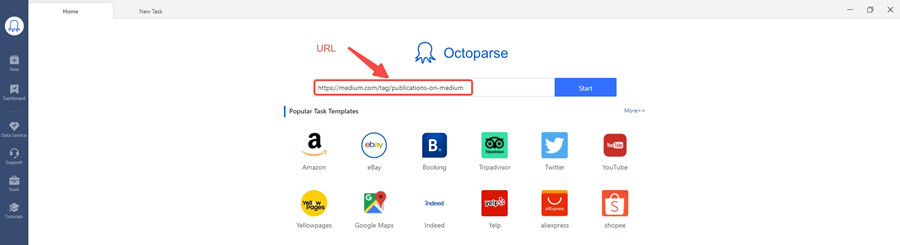
Étape 1 : Ouvrez le site Web de votre choix dans le navigateur intégré d’Octoparse
Chaque flux de travail dans Octoparse commence par entrer une page Web. Entrez simplement l’URL de la page type dans la barre de recherche sur l’écran d’accueil et attendez que la page Web s’affiche.
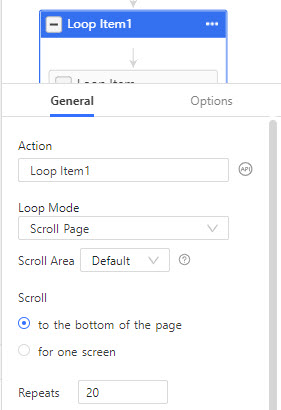
Étape 2 : Ajouter une boucle de défilement de page – pour résoudre le problème du défilement infini des pages
Medium est destiné à charger le contenu de manière dynamique grâce à son modèle de défilement infini. Nous devons donc ajouter un élément de boucle dans la section du flux de travail. Dans l’onglet général de l’élément de boucle, définissez le mode de boucle sur défilement de la page, et répétez le défilement jusqu’au bas de la page 20 fois.
Étape 3 : Extraction des données de la page de la liste des articles
Avant de récupérer le contenu de chaque article, nous devons collecter quelques méta-données de la page de la liste.Cliquez sur le premier bloc d’articles de la liste et choisissez Sélectionner les sous-éléments > Sélectionner tout > Extraire les données pour collecter les données de la liste d’articles. Renommez les champs de données et supprimez les champs inutiles, ce qui nous laisse l’auteur, le titre, la description, la balise et la longueur des articles.
En outre, nous pouvons capturer les URL des articles à l’aide du localisateur XPath.
- Cliquez sur add a custom field dans la section Aperçu des données et sélectionnez Capture data sur le webpage
- Cochez XPath relatif et entrée //a [@aria-label=”Post Preview Title”]
- Enregistrez et exécutez la tâche parentale pour obtenir le premier lot de données (cela prend quelques minutes)
Étape 4 : Utilisez la liste d’URL pour une deuxième tâche de récupération du texte complet
Ensuite, nous devons créer une tâche subordonnée avec les URLs du dernier run de données.
- Retournez à l’écran d’accueil d’Octoparse, cliquez sur + New et sélectionnez Advanced Mode
- Pour les URLs d’entrée, sélectionnez importer de la tâche et localisez le champ de données URL de la première tâche
- Ajouter une action Extract data dans la boucle d’URLs
- Cliquez sur add a custom field dans la section Aperçu des données et sélectionnez Capture data sur le webpage
- Cochez XPath absolu et entrez //article pour localiser l’article entier
Étape 5 : Sauvegardez et exécutez la tâche pour obtenir le deuxième lot de données
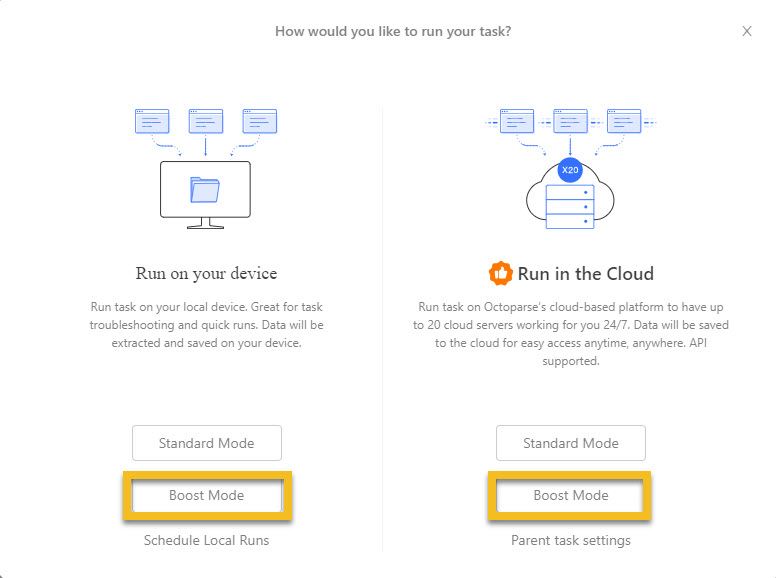
Vous avez peut-être remarqué que nous avons divisé la tâche en deux sous-tâches. Cela a pour but d’augmenter la vitesse de scraping de l’ensemble du projet. Si vous avez affaire à un projet compliqué, il est recommandé de le diviser en sous-tâches et de les exécuter dans le cloud d’Octoparse pour plus de rapidité. Vous pouvez également programmer l’exécution de vos tâches toutes les heures, tous les jours ou toutes les semaines et obtenir des données régulièrement.
Si vous avez des difficultés à créer la tâche vous-même, vous pouvez contacter l’équipe de support Octoparse pour obtenir de l’aide. Amusez-vous bien à scrapper à partir de Medium !



