Dans le domaine universitaire, rien ne semble plus utile aux étudiants, aux chercheurs et aux membres des facultés que Google Scholar pour obtenir suffisamment d’informations pour leurs recherches. Diverses fonctionnalités rendent ce moteur de recherche plus pratique et lui permettent de sauver des vies, comme la littérature académique, les citations en aval et la génération automatique de la version TeX de la Bible.
Parfois, lorsque vous avez besoin d’une grande partie des données de Google Scholar, vous ne pouvez pas le faire en raison de certaines de ses restrictions. Vous pouvez donc utiliser le web scraping pour extraire le contenu de Google Scholar et rechercher un grand nombre d’articles savants et de ressources académiques diverses.
Si vous êtes impatient de les obtenir, suivez ce guide. Il vous aidera à extraire les données de Google Scholar d’une manière plus pratique.
Peut-on scraper Google Scholar ?
Oui, Google Scholar peut être scrappé facilement. Bien que cela semble quelque peu délicat, il est possible de le faire si vous obtenez un scraper Google Scholar fiable pour extraire la littérature académique sans problème.
Cependant, vous devez faire attention aux lois locales sur le scraping de données. Vous devez également tenir compte des droits d’auteur ou de la protection de la vie privée liés à l’utilisation de ces données.
Quelles données peuvent être extraites de Google Scholar ?
Vous pouvez extraire d’énormes quantités de données de Google Scholar, y compris des articles de recherche, et construire automatiquement une base de données de citations en avant et en arrière, ainsi que diverses ressources universitaires, c’est-à-dire ResearchGate, des sites de réseaux sociaux universitaires, et plus encore.
Existe-t-il une API pour Google Scholar ?
Google Scholar ne fournit pas d’accès API officiel pour le web scraping. Le fichier robot.txt de ce moteur de recherche interdit aux web scrapers de récupérer la plupart des pages. Il est supposé être accessible par ses robots ou par des API tierces et n’est pas autorisé pour cette action. Cependant, vous obtiendrez un CAPTCHA à effacer si vous demandez à accéder à certaines informations.
Comment récupérer les données de Google Scholar sans codage ?
Pour récupérer les données de Google Scholar, il est indispensable d’apprendre des langages de codage difficiles. Cependant, vous pouvez utiliser Octoparse, qui peut vous aider à récupérer les données de Google Scholar dans Excel sans codage. Octoparse peut récupérer la page web automatiquement, et vous pouvez appliquer des fonctions avancées comme la pagination, la boucle, le délai Ajax, etc.
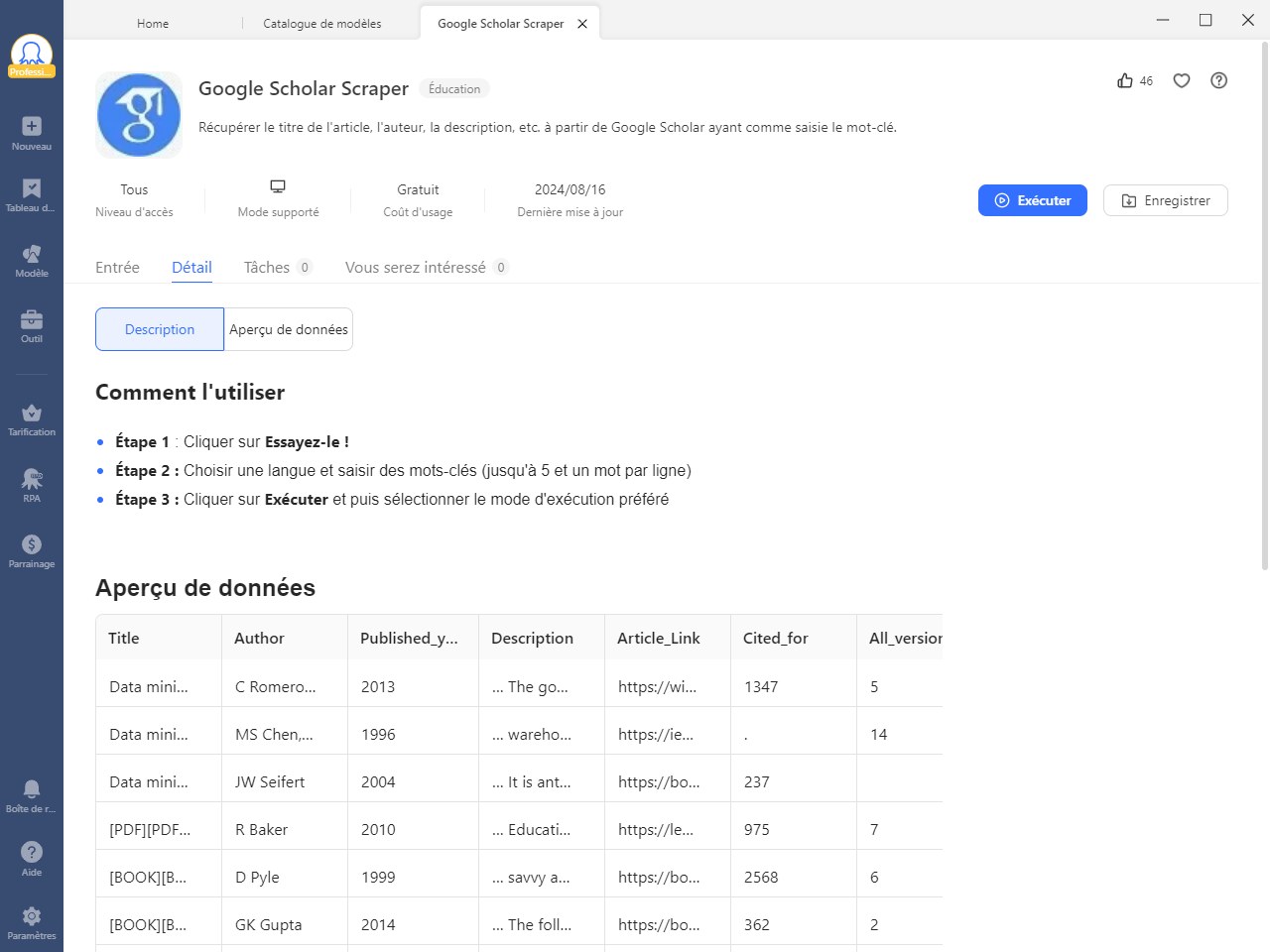
Octoparse fournit également un modèle prédéfini pour l’extraction des informations des articles de Google Scholar qui peut être utilisé directement pour extraire l’ensemble des données. Il suffit d’entrer les mots-clés et d’attendre les résultats. Trouvez-le dans le panneau Template d’Octoparse, et vous pouvez prévisualiser l’exemple de données.
3 étapes pour récupérer des ressources académiques depuis Google Scholar
Téléchargez Octoparse et installez-le sur votre appareil, puis ouvrez un compte gratuitement. Ensuite, suivez les étapes simples ci-dessous ou lisez le guide d’utilisation détaillé sur la récupération des données de Google Scholar. Vous pouvez également regarder la vidéo ici pour vous aider à mieux comprendre.
Étape 1 : Saisir le lien de la page que vous souhaitez extraire de Google Scholar
Tout d’abord, allez sur la page cible de Google Scholar, copiez l’URL et entrez-la dans la barre de recherche d’Octoparse sur l’écran d’accueil. Ensuite, l’URL ciblée sera scrappée automatiquement après que vous ayez cliqué sur le bouton Démarrer.
Étape 2 : Personnaliser le flux de travail pour obtenir plus de données
Après le processus d’auto-détection, un flux de travail sera généré. Vous pouvez apporter des modifications à l’aide du panneau Astuce pour obtenir plus de données. La section de prévisualisation montre ce qui sera scrappé.
Étape 3 : Extraire les données de la page de résultats de recherche de Google Scholar
Cliquez sur le bouton Exécuter pour commencer le scraping et attendez quelques instants. Enfin, vous pouvez télécharger les données extraites dans un fichier Excel/CSV ou les enregistrer directement dans votre base de données.
Vous pouvez également récupérer les résultats de recherche de Google ou de Bing directement si vous souhaitez trouver plus d’informations, qui ne peuvent pas être trouvées dans Google Scholar.
Récupérer Google Scholar avec un modèle prédéfini
En plus de construire un scraper Google Scholar en suivant les étapes ci-dessus, le modèle prédéfini d’Octoparse est une alternative plus efficace pour extraire les données de Google Scholar. Octoparse fournit maintenant une liste de modèles prédéfinis qui couvrent la plupart des plateformes et permettent aux utilisateurs d’extraire des données en masse avec seulement quelques paramètres requis.
En utilisant le modèle prédéfini de Google Scholar Scraper, il vous suffit d’entrer des mots-clés (jusqu’à cinq mots-clés) et de cliquer sur « Démarrer ». Ensuite, vous pouvez obtenir facilement des données telles que le titre de l’article, l’auteur, la description, etc., à partir de Google Scholar.
https://www.octoparse.fr/template/google-scholar-scraper
Scraper Google Scholar à l’aide de Python
Au cas où vous préférez utiliser Python pour extraire les données depuis Google Scholar, apprenez-le en quelques étapes simples.
Étape 1 : Préparez d’abord un environnement virtuel et installez les bibliothèques pour les sélecteurs CSS afin d’extraire les données des balises et attributs pertinents.
Étape 2 : Ajoutez l’extension SelectorGadget pour extraire les données des sélecteurs CSS. Utilisez ensuite les codes Python spécifiques pour extraire les résultats de la recherche organique de Google Scholar.
Étape 3 : Utilisez SerpAPI pour cela, car il peut extraire le titre, le snippet, les informations de publication, le lien vers un article, le lien vers des articles connexes, le lien vers différentes versions d’articles, et les liens au bas de l’article ; BibTeX, EndNote, RefMan, RefWorks, etc.
Étape 4 : En outre, SerpAPI peut également récupérer des informations sur les profils Google Scholar, notamment le nom de l’auteur, le lien, l’affiliation, l’adresse électronique, les centres d’intérêt, la mention « cité par » et l’accès public.
Étape 5 : Une autre donnée importante est le résultat des citations de Google Scholar. Pour cela, une liste temporaire est créée pour stocker les données de citation. Utilisez ces lignes de commande pour itérer sur les résultats organiques et passer l’ID des résultats à la requête de recherche :
Étape 6 : Ensuite, vous devez passer une liste de données renvoyées à partir des résultats organiques et de citation à l’argument Data Framedata et le laisser enregistrer au format CSV.
Étape 7 : Certaines commandes particulières peuvent être utilisées selon vos besoins, soit pour supprimer ou ajouter une colonne dans les données sélectionnées.
Ainsi, le codage Python permettra de récupérer les données de Google Scholar.
En conclusion
Au cours de votre vie académique, vous utilisez fréquemment Google Scholar pour obtenir les derniers et les anciens articles scientifiques et diverses autres ressources académiques, y compris les citations de transmission. Le web scraping de Google Scholar peut ajouter de la valeur à votre parcours académique. Il vous suffit d’utiliser Octoparse pour vous aider à extraire un grand nombre de données des pages web vers vos propres appareils locaux, sans avoir à apprendre des langages de programmation complexes.

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.



