Dans un monde informatique, la média traditionnelle se tourne vers Internet pour développer la presse en ligne et on peut donc facilement lire des nouvelles sur tous les évènements qui se passent dans tous les coins du monde. Cela facilite le travail des chercheurs car ils peuvent maintenant collecter par Internet des nouvelles d’actualités pour alimenter leurs analyses ou rapports. En plus, les agences de presse en profitent pour savoir à temps ce qui se passe dans d’autres endroits. Cependant, vu le nombre volumieux de nouvelles publiées sur des sites de presse innombrables, les collecter manuellement est frustrant et même impossible.
À propos du news scraping (le scraping d’actualités)
Le news scraping est un terme spécifique utilisé pour le scraping mené sur des sites de nouvelles d’actualités dans la fin d’y extraire des articles ou d’autres données. De nos jours, le scraping d’actualités est assez populaires tant entre les chercheurs que les hommes de business. Les professeurs et les étudiants l’utilisent pour mener des analyses ou des études sur un certain évènement social, les économiques ou les poticiens en profitent dans leurs rapports sur l’économie, la politique ou la société, tandis que les travailleurs des entreprises s’en servent pour veiller sur leur réputation ou sur les critiques publiques sur les produits nouvellement lancés, et beaucoup d’autres annonces clés et nécessaires pour les entreprises.
Quand on parle de l’extraction de données, on pose souvent la question de légailité. Donc, est-il légal, le scraping de sites d’actualités ?
Oui, il est légal de récupérer des données publiques et ouvertement disponibles sur des sites d’information. L’extraction de données publiques sur n’importe quel site Web est légale, mais vous devez vous renseigner sur les lois et réglementations locales pour connaître les aspects juridiques de l’extraction de données sur les sites d’actualité.
Certaines données disponibles sur les sites d’actualités peuvent être privées et ne pas être autorisées à être scrappées parce qu’elles ont été restreintes par les autorités mondiales de réglementation des données.
Pourquoi choisir Octoparse pour le scraping d’actualités ?
Pour effectuer le scraping d’actualités, de nombreux outils sont à votre disposition, parmi lesquels Octoparse.
Octoparse est un des logiciels les plus populaires d’extraction de données, qui est disponible sur Windows et Mac. En tant que outil de non-codage, Octoparse a pour but de rendre le web scraping accessible à tous pour que tout le monde, surtout ceux qui n’ont pas de connaissance technique mais ont besoin d’un grand nombre de données, puissent scraper les données sans codage.
Facile à utiliser
Octoparse est premièrement réputé par sa simplicité. Grâce à son interface “pointer-cliquer”, les utilisateurs peuvent extraire les données en trois étapes et transformer les pages Web en feuilles de calcul structurées en quelques clics. Dans la fin de faciliter l’utilisation, Octoparse propose des modèles de web scraping prêts à l’usage. Et avec la fonction de détection automatique, les utilisateurs peuvent régler facilement les sites web que les modèles ne couvrent pas encore.
Puissant dans l’extraction de données
Octoparse peut traiter tous les sites Internet, quelle que soit la structure, la façon de chargement de contenu : défilement infini, liste déroulante, AJAX, authentification de connexion. De plus, Octoparse est équipé d’un Service Cloud, permettant une extraction plus rapide et une extraction basée sur Cloud. Donc, il n’y a pas de besoin de veille manuelle et on peut exécuter les tâches de scraping 24/7, et plannifier les tâches de scraping à à n’importe quel moment, quotidiennement, hebdomairement, et à n’importe quelle fréquence. Egalement sont disponibles les proxies IP, aidant à éviter tout blocage des IPs des utilisateurs. En plus, Octoparse offre également des solutions de Captcha pour qu’on puisse scraper des sites difficiles.
Par conséquent, vous pouvez récupérer un grand nombre de données d’actualités avec Octoparse sans effort.
Premièrement, récupérer les données depuis de multiples canaux. Vous pouvez l’utiliser pour la collecte de communiqués de presse, de revues universitaires, d’actualités d’entreprises, de newsletters, d’articles d’actualité, de blogs, d’éditeurs et de magazines, et bien plus encore, à partir d’un large ensemble de sources de données, avec la plus grande facilité.
Deuxièmement, extraire divers champs de données. Avec Octoparse, vous pouvez non seulement enregistrer l’article original des nouvelles, mais également des métadonnées, comme titre, description, date de publication, auteur, URL des images, catégories, URL des références, flux RSS, agrégation de nouvelles pertinentes par mots-clés et plus encore.
Comment extraire tant le contenu que les métadonnées des nouvelles sans codage ?
Sans plus attendre, voyons maintenant comment utiliser Octoparse pour extraire le contenu et les métadonnées des nouvelles sans codage.
Dans cette partie, je vais choisir le site bfmtv comme un le site d’exemple. Si vous y êtes intéressé pour le scraping d’actualités, je vous invite à télécharger Octoparse et l’installer pour suivre les étapes suivantes, et vous finirez par collecter les données dont vous avez besoin.
Étape 1 Entrer l’URL dans Octoparse
Ici, nous ciblons la réforme des retraites. Il vous faut faire cette recherche dans votre navigateur sur le site bfmtv.com, et puis le copier-coller dans la page d’accueil d’Octopase. Ensuite, cliquer sur “Start” pour commencer notre scraping d’aujourd’hui.
Mon URL est https://www.bfmtv.com/economie/economie-social/reforme-des-retraites_DN-202108310622.html
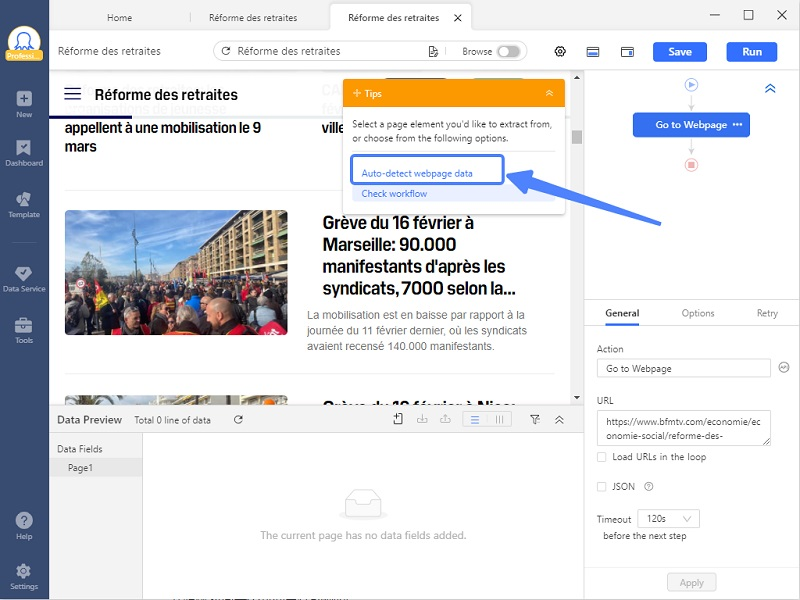
Étape 2 Lancer l’auto-détection
La nouvelle version d’Octoparse est équipée dans cette fonctionnalité merveilleuse. Il suffit aux utilisateurs de simplement cliquer sur “Auto-detect webpage data” pour que Octoparse détecte la structure de la page et puis crée automatiquement un workflow pour vous. Ainsi, on a échapé à la création de la pagination et de la boucle (loop).
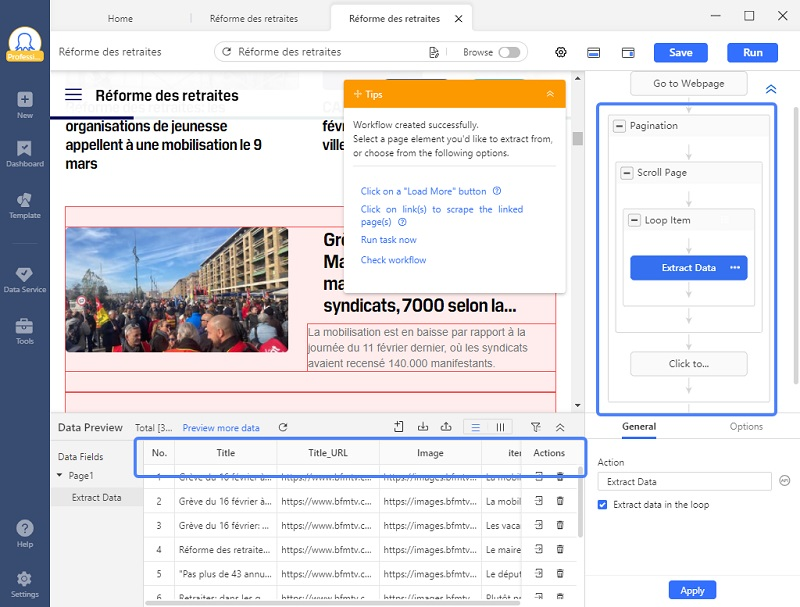
Étape 3 Checker le workflow créé par Octoparse
Par la capture suivante, on voit clairement que la pagination et la boucle sont déjà comprises dans le workflow. De plus, vous pouvez surnommer les champs de données dans le panneau de “Data Preview” au bas. S’il y a des champs indésirés, vous pouvez également les supprimer.
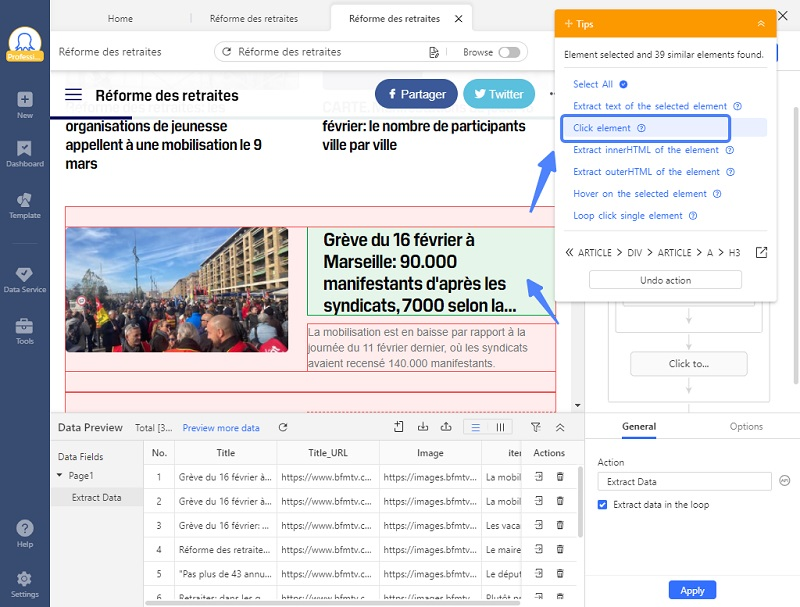
Étape 4 Entrer dans la page d’article complet
Cliquer sur le premier titre et sélectionner “Click element”.
Étape 5 Extraire les métadonnées
Cliquer le nom de l’auteur, et puis choisir “Extract text of the selected element”. Ensuite, répéter la même étape pour d’autres champs de données qui vous intéressent, comme nom de l’auteur, data de publication, balise, etc.
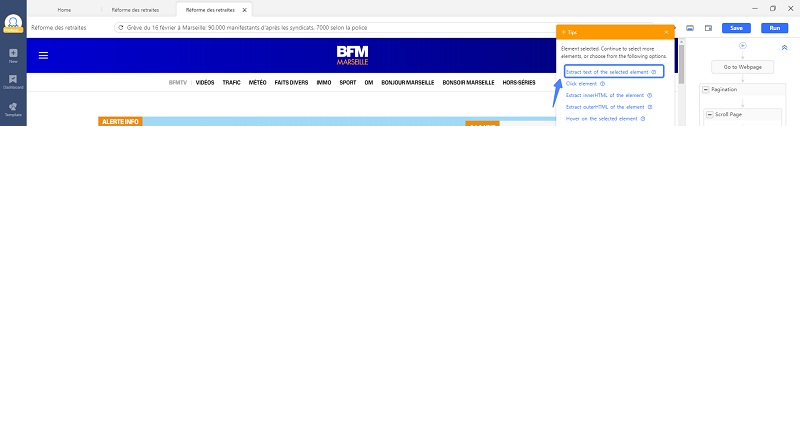
Étape 6 Extraire le texte complet
En inspectant le code HTML, on peut savoir que le texte complet est inséré dans un [div], par cela, le Xpath est //div[@id=’content_progress’]/div/div
Curieux de savoir comment j’ai écrit ce Xpath ? Veuillez consulter ce tutoriel sur Xpath.
1 – Cliquer sur ce petit icône, et puis sélectionner “Capture data on the page”.
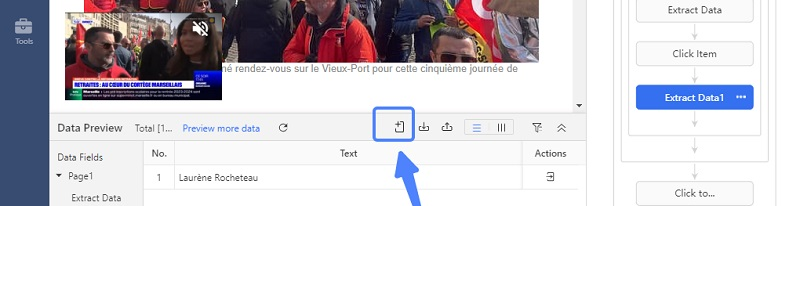
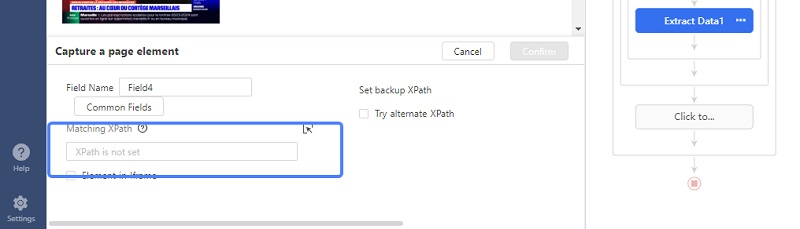
2 – Entrer le Xpath de l’article complet. Et volà !
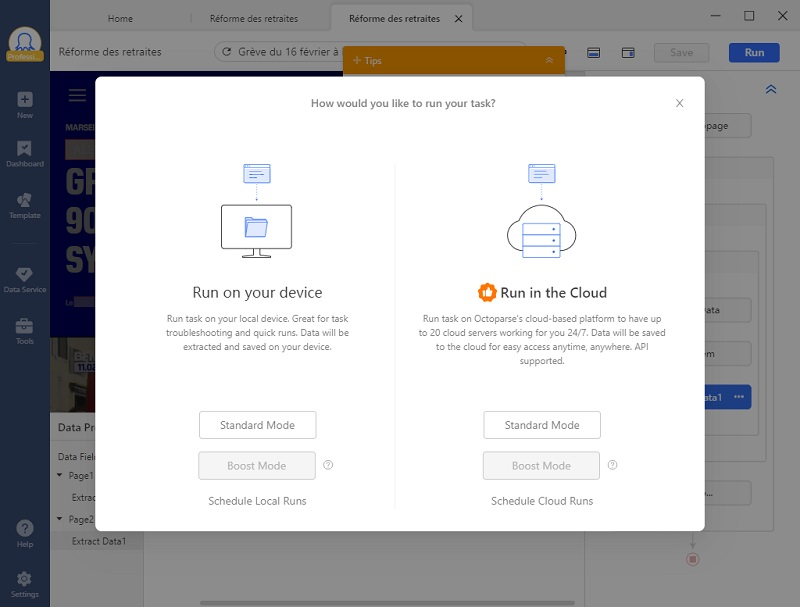
Étape 7 Lancer la tâche de scraping
Cliquer sur “Run” en haut à droite, et choisir le mode selon vos besoins.
Étape 8 exporter les données
Les données peuvent être téléchargées dans des formats comme Excel, CSV ou être exportées vers d’autres systèmes comme Google Sheets, Zapier, etc.
Voilà mes résultats.

C’est tout ! J’espère que ces étapes vous servent d’un guide dans votre extraction de données. En effet, cela ne se limite dans le scraping des nouvelles d’actuaités, vous pouvez également l’employer pour extraire l’article complet des blogs, dse réseaux sociaux ou d’autres. Allez faire votre découerte !
Des sites de nouvelles d’actualités en France
Les sites de nouvelles d’actualités sont un des sites qu’on consulte presque tous les jours.
Voici une liste de sites d’actualités en France, classés par nombre de visiteurs selon les données de SimilarWeb en janvier 2022
- Le Figaro – 132 millions de visites mensuelles
- Le Monde – 109 millions de visites mensuelles
- L’Équipe – 40 millions de visites mensuelles
- 20 Minutes – 36 millions de visites mensuelles
- BFM TV – 33 millions de visites mensuelles
- CNEWS – 17 millions de visites mensuelles
- Franceinfo – 16 millions de visites mensuelles
- RMC Sport – 11 millions de visites mensuelles
- Capital – 9 millions de visites mensuelles
- Les Echos – 8 millions de visites mensuelles
- La Croix – 6 millions de visites mensuelles
- Sud Ouest – 6 millions de visites mensuelles
- Le Parisien – 5 millions de visites mensuelles
- Ouest-France – 5 millions de visites mensuelles
- Libération – 4 millions de visites mensuelles
Il convient de noter que ces chiffres sont sujets à des variations et que différentes sources peuvent avoir des estimations différentes.
La technique de web scraping sert d’un outil d’efficacité d’extraction de données. Après cela, c’est le voyage de découvrir la valeur qui est cachée dans les données. Bon scraping et bon travail !



