Le marché financier est un lieu de risques et d’instabilité. Il est difficile de prévoir l’évolution de la courbe et parfois, pour les investisseurs, une seule décision peut être déterminante. C’est pourquoi les praticiens expérimentés ne perdent jamais de vue les données financières. Encore, les crypto-monnaies font également l’objet d’une grande attention aujourd’hui.
Sans une base de données bien structurée, nous ne pouvons pas suivre l’immense quantité d’informations dont nous disposons. Le scraping de données est une solution pour récupérer de données complètes au bout des doigts. Par exemple, on peut scraper le site CoinGecko pour extraire en temps réel le prix des cryptomonnaie. Dans cet article, on verra comment on peut obtenir les données financières sans Python.
Qu’est-ce que nous recherchons quand nous explorons des données financières ?
Lorsqu’il s’agit de scraper des données financières, les données boursières sont sous les feux de la rampe de l’attention. Et il y a de plus, les prix de négociation et les changements de titres, de fonds communs de placement, de contrats à terme, de crypto-monnaies, etc. Les états financiers, les communiqués de presse et autres nouvelles liées aux affaires sont également des sources de données financières que les gens vont extraire.
Pourquoi extraire des données financières ?
Les données financières, lorsqu’elles sont extraites et analysées en temps réel, peuvent fournir de riches informations pour les investissements et les transactions. Et des personnes occupant des postes différents extraient des données financières à des fins diverses.
- Prévision des marchés boursiers
Les organisations boursières s’appuient sur les données des portails de commerce en ligne tels que Yahoo Finance pour tenir des registres des prix des actions. Ces données financières aident les entreprises à prévoir les tendances du marché et à acheter/vendre des actions pour réaliser les meilleurs profits. Il en va de même pour les transactions sur les contrats à terme, les devises et autres produits financiers. Avec des données complètes à portée de main, les comparaisons croisées deviennent plus faciles et une vue d’ensemble se dessine.
- Recherche sur les actions
“Ne mettez pas tous les œufs dans un panier.” Les gestionnaires de portefeuille font des recherches sur les actions pour prédire la performance de plusieurs titres. Les données sont utilisées pour identifier le schéma de leurs variations et développer ensuite un modèle de trading algorithmique. Avant d’arriver à cette fin, une grande quantité de données financières seront impliquées dans l’analyse quantitative.
- Analyse des sentiments sur le marché financier
L’extraction de données financières n’est pas seulement une question de chiffres. Les choses peuvent évoluer sur le plan qualitatif. Nous pouvons découvrir que le présupposé soulevé par Adam Smith est intenable – les gens ne sont pas toujours économiques, ou disons, rationnels. L’économie comportementale révèle que nos décisions sont susceptibles d’être influencées par toutes sortes de biais cognitifs, voire d’émotions.
En utilisant les données des actualités financières, des blogs, des messages pertinents sur les médias sociaux et des critiques, les organisations financières peuvent effectuer une analyse des sentiments pour saisir l’attitude des gens envers le marché, ce qui peut être un indicateur de la tendance du marché.
Comment extraire des données financières sans Python ?C’est parti !
Si vous n’êtes pas un programmeur, restez à l’écoute. Laissez-moi vous expliquer comment vous pouvez récupérer des données financières avec Octoparse. Yahoo Finance est une source intéressante pour obtenir des données financières complètes et en temps réel. Je vais vous montrer ci-dessous comment récupérer des données sur le site.
En outre, il existe de nombreuses sources de données financières contenant des informations actualisées et précieuses que vous pouvez extraire, telles que Google Finance, Bloomberg, CNNMoney, Morningstar, TMXMoney, etc. Tous ces sites sont des codes HTML par nature, ce qui signifie que tous les tableaux, articles de presse et autres textes/URL peuvent être extraits en masse par un outil de scraping web.
Il y a 3 façons d’obtenir les données :
Utiliser un modèle de web scraping prêt à emploi
Construire votre robot de web scraper
Faire appel à des services de données tiers
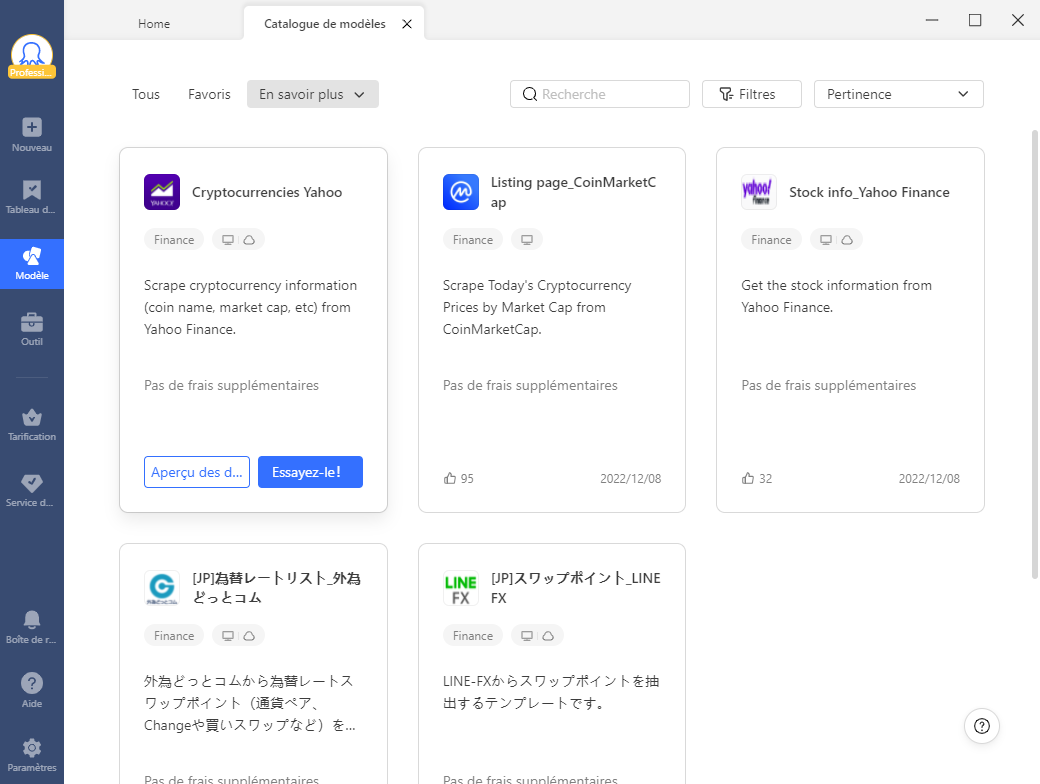
1. Utiliser un modèle de web scraping pour le site Yahoo Finance
Afin d’aider les débutants à s’initier facilement au web scraping, Octoparse propose une série de modèles de web scraping. Ces modèles sont des crawlers préformants prêts à l’emploi. Les utilisateurs peuvent choisir l’un d’entre eux pour extraire instantanément des données des pages concernées. Jusque maintenant, Octoparse propose des modèles qui couvrent la plupart des sites populaires de tous les catégories.
https://www.octoparse.fr/template/yahoo-recherche-scraper
S’agissant de la finance, on compte pour l’instant deux des sites les plus importants : Yahoo Finance, CoinMarketCap. Vous pouvez lire l’introduction pour comprendre ce que vous pouvez obtenir avec ce modèle. Cliquez simplement sur “essayer” et entrez l’URL ou le mot-clé cible, vous obtiendrez les données désirées en quelques minutes.
2. Construire un web scraper à partir de zéro en 2 étapes
Si les modèles ne couvrent pas encore votre site cible ou ne permettent d’obtenir les données désirées, vous pouvez également construire vous-même un web scraper. Pas de souci ! Ce n’est pas aussi difficile que vous imaginez ! Même les non-codeurs peuvent facilement le créer avec la détection automatique performante proposée par Octoparse. Créer un web scraper personnalisé est très flexible pour l’extraction de données. Si la récollecte de données est votre besoin fréquent, la partie suivante vous est indispensable : en effet, il suffit de suivre les étapes simples et vous pourriez l’utiliser sur d’autres sites Web.
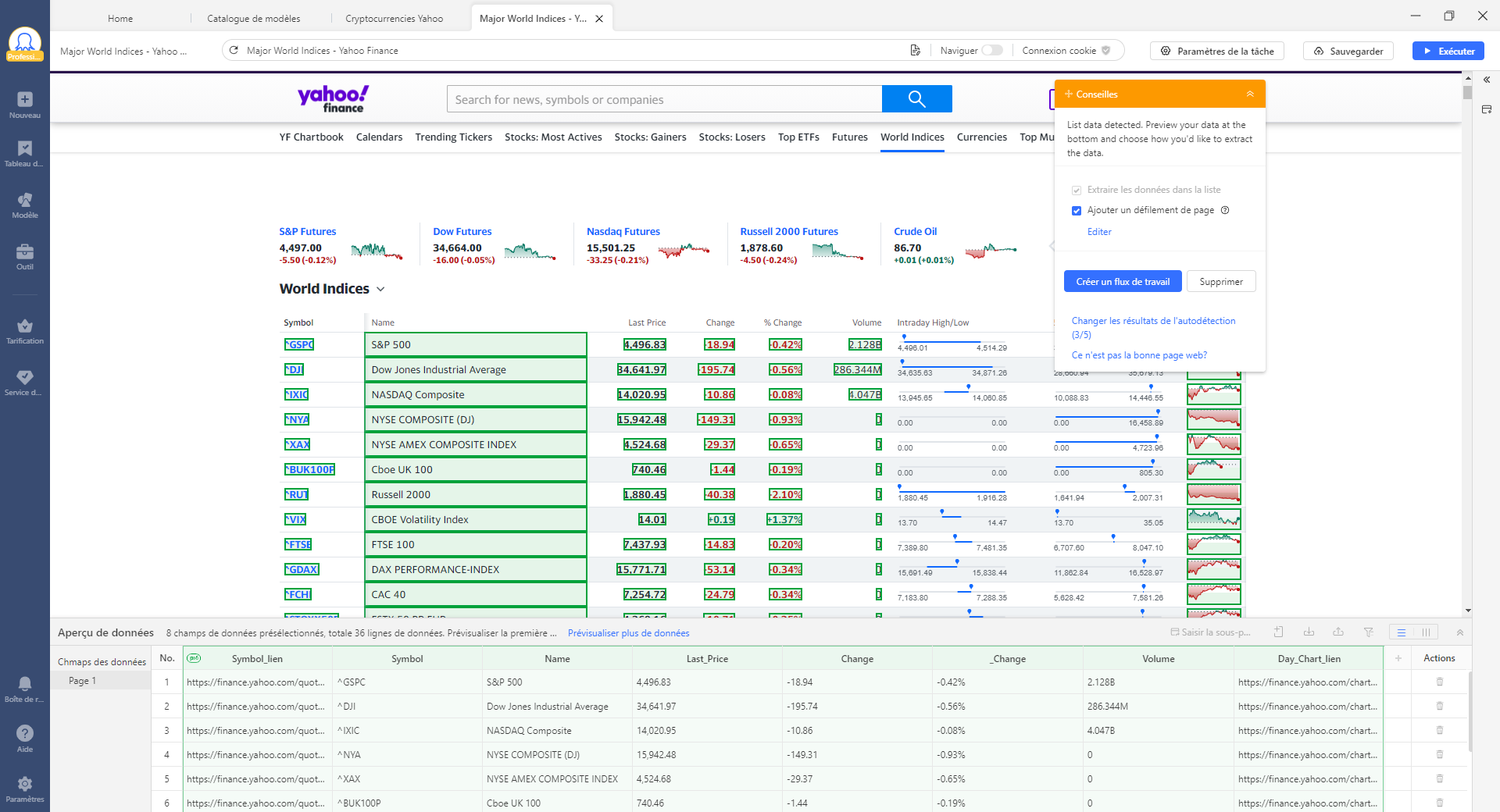
Étape 1 : Entrer l’URL cible et démarrer la détection automatique
Après que l’URL est entrée, le robot chargera le site web dans le navigateur intégré, et un clic sur le panneau de conseils peut déclencher le processus d’autodétection. Le robot va détecter le contenu des pages Web et extraire les données qu’il croit nécessaire pour vous. Etant donné que toutes les données des pages sont détectées, vous auriez plusieurs choix sur les résultats.
URL d’exemple : https://finance.yahoo.com/world-indices
Étape 2 : Accomplir le flux de travail
Faire des adjustements s’il y a besoin, par exemple, supprimer certains champs de données peu importants, surnommer les champs ou bien d’autres.
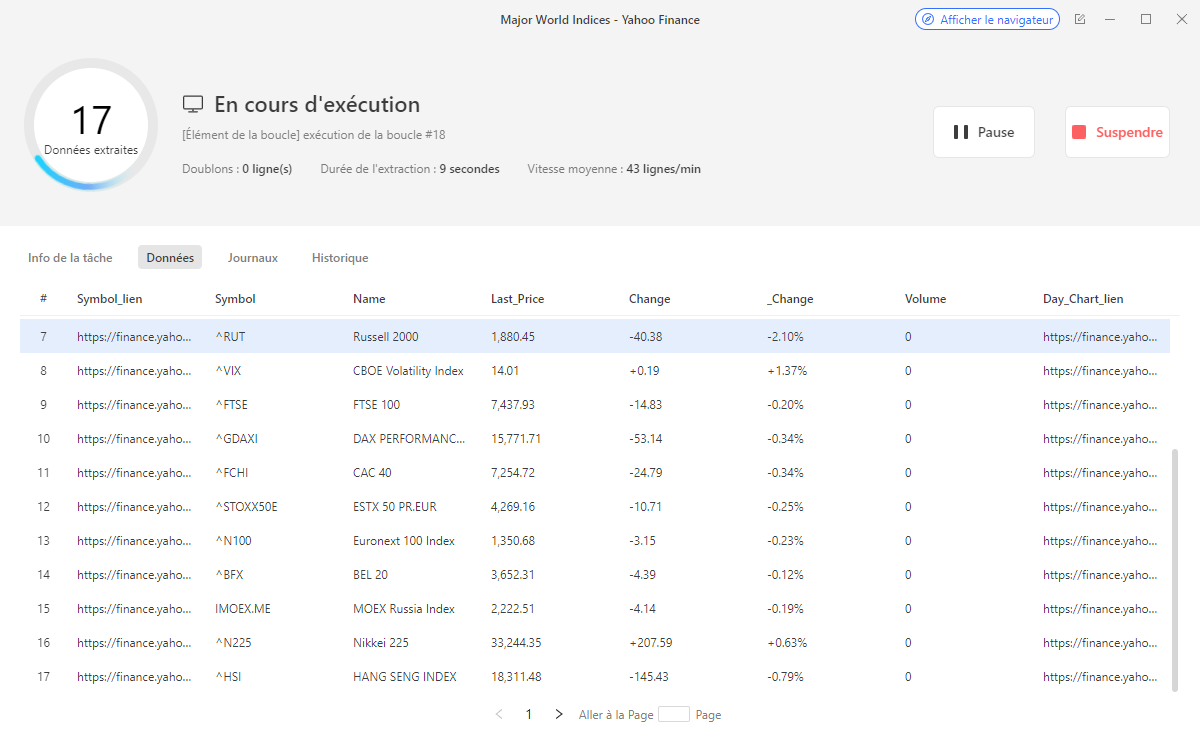
Étape 3 : Exécuter le web scraper ou exporter les données.
Quand le web scraper est prêt, vous pouvez cliquer sur “Exécuter” pour commencer l’extraction de données. Comme vous pouvez le voir dans la pop-up, toutes les données ont été extraites avec succès. Maintenant, vous pouvez exporter les données dans Excel, JSON, CSV, ou vers votre base de données via les APIs.
3. Externaliser l’extraction de données à un tiers
Si vous devriez extraire de temps en temps des données financières en quantité relativement faible, vous trouverez peut-être du plaisir à construire vos propres crawlers. Cependant, si vous avez besoin de données volumineuses pour une analyse approfondie, par exemple des millions de lignes, et que vous avez un haut niveau de précision, il est préférable de confier vos besoins en matière de scraping à un groupe de professionnels fiables.
Pourquoi les services de données ?
- Économie de temps et d’énergie
La seule chose que vous devez faire est d’indiquer clairement au fournisseur de services les données que vous souhaitez. Une fois cela fait, l’équipe du service de données s’occupera du reste, sans problème. Vous pouvez vous plonger dans votre activité principale et faire ce que vous savez faire. Laissez des professionnels faire le travail de scraping pour vous.
- Pas de difficulté d’apprentissage ni de problèmes techniques
Même l’outil de scraping le plus simple demande du temps pour être maîtrisé. L’environnement en constante évolution des différents sites Web peut être difficile à gérer. Et lorsque vous faites du scraping à grande échelle, vous pouvez rencontrer des problèmes tels que l’interdiction d’IP, la faible vitesse, les données en double, etc. Le service d’extraction de données peut vous libérer de ces problèmes.
- Aucune violation à la loi
Si vous ne prêtez pas suffisamment attention aux conditions d’utilisation des sources de données que vous exploitez, vous risquez de vous attirer des ennuis. Avec le soutien d’un conseiller juridique expérimenté, un fournisseur de services de web scraping professionnel travaille dans le respect des lois et l’ensemble du processus de scraping sera mis en œuvre de manière légitime.
En conclusion
Les données n’ont pas de sens que quand elles sont cumulées et sont analysées. L’industrie financière a besoin de données pour prévoir l’intendance, analyser le marché, comprendre les acteurs, etc. Obtenir les données avec Python est bien sûr un méthode possible et relativement largement utilisé. Mais avec le développement du secteur de web scraping, il devient un outil accessible à tous, même les non-codeurs. Pour extraire les données financières, vous pouvez utiliser un modèle déjà fait, créer un web scraper par vous-même, ou l’externaliser à un tier si vous avez un grand projet.