Avec l’aide du web scraping, les particuliers et les entreprises peuvent désormais accéder à d’énormes quantités de données provenant d’un large éventail de sources dans divers secteurs d’activité. Le Monde, l’un des médias les plus réputés en France, est une bonne source de web scraping. Vous pouvez y recueillir des tonnes d’informations, notamment des articles d’actualité et des articles de blog et des commentaires. Ensuite, ces données peuvent être appliquées à une variété d’initiatives impliquant l’apprentissage automatique, l’analyse des sentiments, la recherche, l’agrégation de nouvelles et d’autres idées basées sur les données.
Dans cet article, on va voir un moyen très très simple de récupérer les données d’actualités depuis le site Le Monde
Le Monde.fr – site d’actualités en France et dans le monde
Le Monde.fr est un journal américain bien connu. Il s’est forgé une excellente réputation grâce à ses reportages détaillés et à son contenu varié couvrant un large éventail de sujets, tels que la politique, la science, la technologie et bien d’autres encore. Sa plateforme numérique est réputée pour être conviviale et riche en données, ce qui en fait une excellente ressource pour trouver des informations rapides, précises et de grande qualité. Ce site est une cible de choix pour le web scraping en raison de sa couverture inégalée de l’actualité locale, nationale et internationale.
Pourquoi on scrape le Monde
Les gens scrappent le site de Le Monde pour plusieurs raisons.
Les chercheurs et les universitaires effectuent des analyses de texte ou examinent les tendances à des fins de recherche historique et des études de la société. Les entreprises, en particulier celles qui s’occupent de la surveillance des médias, de la gestion de la réputation ou de l’analyse des sentiments, tirent parti des données récupérées sur le web pour obtenir des informations commerciales. Elles aident également les journalistes et les conservateurs de contenu qui utilisent l’agrégation de nouvelles à organiser leur contenu de manière plus efficace. Tout bien considéré, le scraping en ligne permet de prendre des décisions fondées sur des données exactes et opportunes, ce qui confère aux entreprises et aux individus un avantage concurrentiel majeur.
Quelles sont les données que vous pouvez extraire de Le Monde ?
Articles d’actualité : En tant qu’élément fondamental de tout média, la qualité et l’exhaustivité des articles d’actualité sont primordiales. Vous pouvez extraire diverses données telles que l’article intégral, le titre, le chapeau, l’auteur, la date de publication et l’URL de tous les articles. Cela permet d’obtenir une vue approfondie de divers secteurs tels que la politique, l’économie, la technologie, la santé et bien d’autres encore. Les données acquises fournissent des informations précieuses sur le sujet, le style d’écriture et la position des articles dans les différentes catégories.
Images : Les éléments visuels améliorent considérablement le potentiel narratif des articles d’actualité. En récupérant les images associées aux articles, y compris leurs légendes et les métadonnées potentielles, on obtient non seulement des informations auxiliaires, mais aussi une compréhension de la manière dont les médias visuels sont utilisés pour améliorer la présentation de l’histoire. Il peut s’agir d’une riche source de données pour des analyses visuelles et une compréhension plus complète du contexte du reportage.
Tags et catégories : Les articles d’actualité sont assortis de balises spécifiques et relèvent de certains rubriques, qui servent de référence rapide au contenu et au contexte de l’article. Le scrapping de ces balises et catégories peut offrir une perspective utile sur les sujets en vogue et peut aider à identifier des modèles dans les thèmes des articles au fil du temps, avec des implications potentielles pour comprendre les intérêts et les préférences des lecteurs.
Informations sur l’auteur : Les données sur les auteurs constituent un sous-ensemble essentiel des données d’actualité. La collecte d’informations sur les auteurs, telles que leur désignation, leur biographie et d’autres articles, peut faciliter une analyse plus approfondie des perspectives et des préjugés qui peuvent colorer les reportages d’actualité. Cela peut également fournir des indications sur les modèles de paternité, les thèmes récurrents dans les œuvres d’auteurs spécifiques et leur impact sur l’engagement du public.
Trois étapes faciles pour scraper Le Monde
Octoparse est un puissant outil de scraping web conçu pour accéder à divers types de données et les extraire de différentes structures de sites web. Il présente un avantage certain en raison de ses capacités complexes, qui incluent la prise en charge d’AJAX, de JavaScript, de cookies, de sessions et de redirections. Il convient aussi bien aux personnes qui ne codent pas qu’aux experts, car il ne nécessite aucune compétence en matière de codage. Le programme se distingue par sa capacité à collecter de manière efficace et fiable les données, malgré les défis habituels du scraping. Voyons maintenant les instructions détaillées pour utiliser ce puissant outil au maximum de son potentiel.
Étape 1 : Créer une nouvelle tâche
Dans Octoparse, entrez l’URL ou les URL de Le Monde.fr que vous voulez scraper. Ensuite, cliquez sur « Démarrer » pour créer une nouvelle tâche de scraping d’articles ou de nouvelles.
Étape 2 : Sélectionner les données et construire un scraper
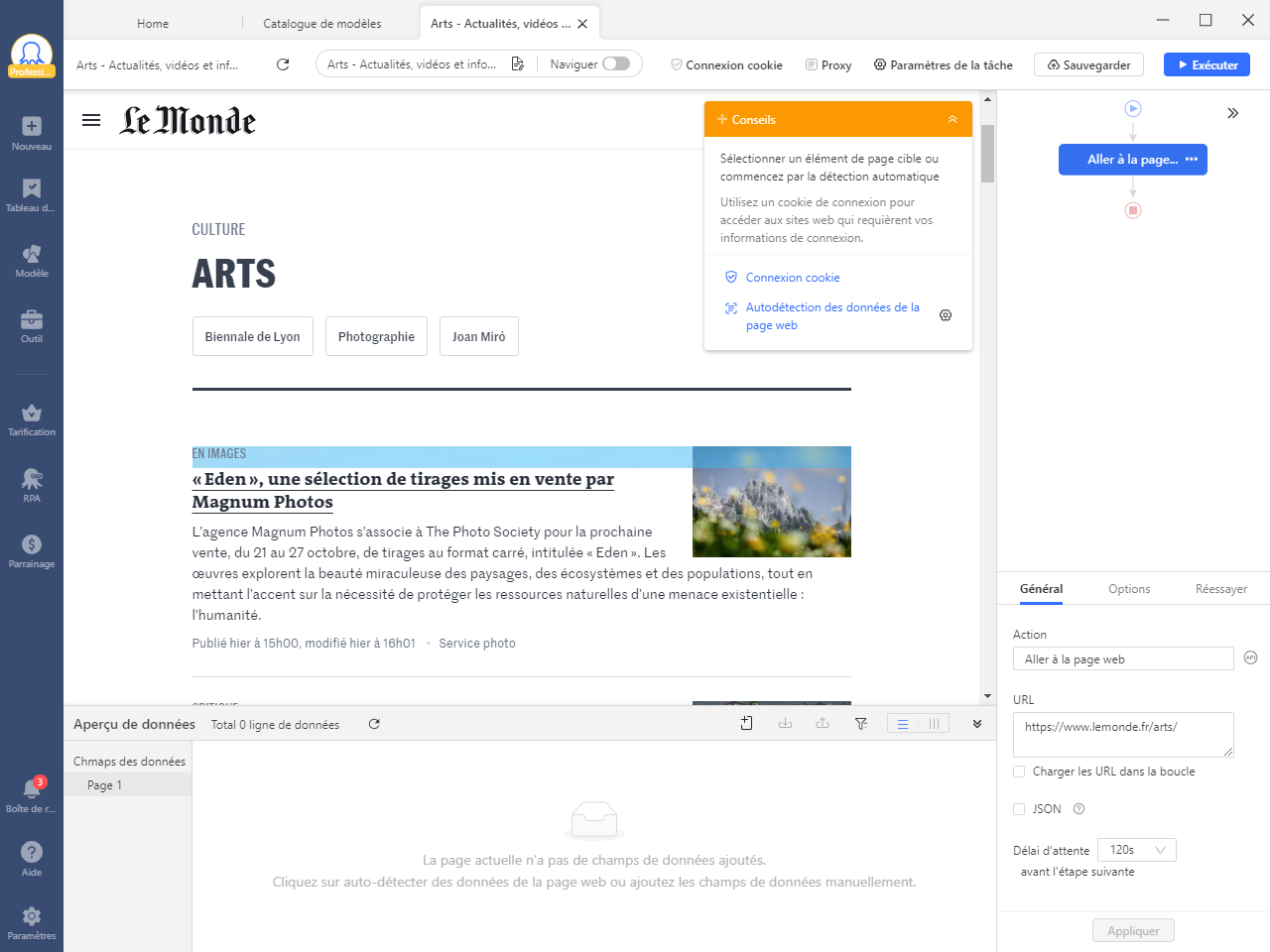
Une fois le chargement de la page web terminé, cliquez sur « auto-détection » dans le panneau de conseils pour identifier les données qui peuvent être scrappées ou sélectionnez manuellement les données requises si la fonction d’auto-détection n’identifie pas avec précision les informations souhaitées. Cliquez sur « Créer un flux de travail » lorsque toutes les données d’actualité souhaitées ont été spécifiées. Un flux de travail apparaît alors sur le côté droit. Il présente toutes les fonctions et actions du scraper.
Cliquez sur chaque action pour voir si le scraper fonctionne comme prévu. Vous pouvez également ajouter de nouvelles activités pour vous assurer qu’il fonctionne bien pour vous.
Étape 3 : Extraire les données depuis LeMonde
Cliquez sur le bouton « Démarrer » pour lancer le scraper après avoir vérifié toutes les informations. Le scraper commencera à collecter les données d’actualités ou d’articles depuis le site de Le Monde.fr en fonction des paramètres que vous avez définis précédemment. Une fois le processus de récupération des données terminé, les informations collectées peuvent être téléchargées au format Excel, CSV ou tout autre format.
Conseils : Voici d’autres ressources sur le scraping d’actualités comme comment scraper des blog posts, comment construire une agrégation de contenu efficace et plus encore qui peuvent vous aider avec votre scraping d’actualités et d’articles sur le web !
En plus du méthode de créer un web scraper par vous-même, je voudrais vous introduire les modèles prêts à l’emploi. Ce sont des tâches de web scraping qui sont pré-construites par l’équipe d’experts, protégeant les utilisateurs du travail d’établir un flux de travail de web scrapingg par eux-mêmes. Ces modèles couvrent presque tous les sites populaires les plus scrapés comme Google Recherche, Amazon, Pagesjaunes, etc, y compris le site d’actualités LeMonde.fr.
https://www.octoparse.fr/template/le-monde-rubrique-scraper
Son utilisation est très simple. Il vous suffit de cliquer dessus pour ouvrir le modèle, saisir les URLs de LeMonde selon l’instruction et démarrer la tâche, en attendant que le robot vous extrait les données d’actualités.
Ce modèle cible les champs de données comme suivant :
- Titre
- Chapeau
- URL des images
- Date de publication
- Auteur
- Lien d’auteur
- Lien de l’article
Au cas où vous souhaitez extraire l’intégralité des articles d’actualités, vous pouvez profiter d’un autre modèle pour faciliter les choses.
https://www.octoparse.com/template/smart-article-scraper
- Étape 1 : saisir les URLs des articles
- Étape 2 : lancer la tâche
- Étape 3 : obtenir les articles intégraux
Ce modèle est utilisé pour extraire les articles publics. Si votre besoin consiste à extraire des articles exclus aux premium, veuillez contacter toujours l’équipe de support pour trouver une solution personnalisée.
En conclusion
En résumé, la méthode consistant à utiliser Octoparse pour scraper lemonde est très utile car elle élimine la tâche laborieuse de la collecte manuelle de données, fournissant des données rapides et précises pour une prise de décision éclairée. Le web scraping est une stratégie solide pour la collecte de données de Le Monde.fr et d’autres sources d’information. Cependant, il est important de respecter les règles du site web, y compris les robots.txt, les lois sur les droits d’auteur et de garantir une utilisation éthique des données collectées. Pour des opérations de scraping plus complètes, envisagez l’application de fonctionnalités avancées offertes par des outils comme Octoparse, notamment la rotation des adresses IP, la planification des tâches et l’utilisation d’expressions régulières, entre autres.
Bon scraping !