Le web scraping, également appelé extraction de données, consiste à utiliser un logiciel pour extraire des données depuis des sites web en ligne. Cette technique peut être utilisée dans la collection des articles d’actualité, des billets de blog, des articles et d’autres éléments connexes à partir de sources en ligne. Le web scraping est largement utilisé, principalement en raison de sa capacité à extraire une grande quantité de données en peu de temps.
Cet article explique ce qu’est le web scraping de nouvelles et d’articles et son importance. Et puis, il explore les aspects juridiques et fournit un tutoriel simple sur la manière de scraper efficacement des nouvelles et des articles.
Qu’est-ce que le web scraping d’actualités et d’articles ?
Le web scraping d’actualités et d’articles commence par la collecte des URL des pages où se trouvent les données requises. Ensuite, un outil ou un script de web scraping permet de récupérer le contenu souhaité et de le stocker en vue d’une utilisation ultérieure. Ce processus permet aux agences de presse, aux journalistes, aux chercheurs et aux entreprises de se tenir au courant des dernières informations, de surveiller rapidement de nombreuses sources d’information, de suivre les concurrents et même de fournir des données pour les algorithmes d’apprentissage automatique.
Les sites web d’actualités et d’articles à scraper
Fréquemment mis à jour avec un contenu sensible au temps, les sites web d’actualités sont parmi les sites web les plus fréquemment scrappés. Les sources d’information mondiales telles que CNN, le New York Times et le Washington Post en font partie. Il existe également des plateformes d’information spécialisées telles que Bloomberg pour les informations financières. Ces sites fournissent un large éventail de données allant de l’actualité locale à l’actualité internationale.
Les sites d’articles fournissent des connaissances approfondies sur des domaines spécifiques. Par exemple, les éditoriaux et les articles d’opinion de sites tels que Medium, ainsi que les articles informatifs de BDM. L’extraction de ces articles s’avère utile pour la curation de contenu, l’analyse de la concurrence ou l’acquisition de connaissances spécifiques à un secteur d’activité.
L’importance du scraping d’articles et d’actualités sur le web
Dans un monde numérique où tout va très vite, il est important de se tenir au courant des dernières informations. Le web scraping représente une transformation importante dans l’accès et l’utilisation des nouvelles et du contenu en ligne grâce à sa capacité à automatiser et à simplifier la collecte de nouvelles et d’articles.
Agrégation de nouvelles : Le web scraping joue un rôle essentiel dans le regroupement d’informations et d’articles en ligne provenant de diverses sources sur une plate-forme unique pour un accès pratique. Le web scraping réalise tout cela automatiquement, ce qui permet de gagner du temps par rapport au processus laborieux de localisation, de compilation et d’organisation manuelles d’articles provenant de nombreux sites web d’actualités. Pour les journalistes, les chercheurs ou toute autre personne souhaitant se tenir au courant des événements mondiaux, cette méthode est très utile et permet de gagner du temps.
Recherche universitaire : Les chercheurs ont souvent besoin d’un grand nombre d’informations provenant d’ouvrages publiés et de publications sur le web. Les chercheurs peuvent récupérer de manière plus précise et plus efficace des données provenant d’articles particuliers se rapportant à leur sujet d’étude en utilisant des techniques de web scraping. Le web scraping peut également aider à identifier des modèles, des tendances et des connexions entre différents sujets ou secteurs de recherche, ce qui peut conduire à la découverte de nouvelles pistes de recherche.
Analyse des sentiments : L’analyse des sentiments permet d’extraire, de mesurer et d’identifier des données provenant de diverses sources à l’aide de techniques de traitement du langage naturel. Dans ce processus, le web scraping est un moyen fiable de collecter les données nécessaires, en particulier lorsqu’il s’agit d’avis de clients, de flux de réseaux sociaux ou d’articles d’actualité. L’automatisation du processus permet d’obtenir des données plus précises sur les sentiments du public à l’égard des entreprises, des produits ou des événements. Les entreprises peuvent utiliser les données recueillies pour gérer la réputation de leur marque, anticiper les tendances du secteur, prendre des décisions fondées sur des données et mieux comprendre les expériences des consommateurs.
La légalité du scraping de données sur les sites d’actualités et d’articles
Étant donné qu’elle dépend souvent d’une série de critères, la légalité de la récupération de données sur les sites web d’actualités et d’articles peut être une question compliquée. Le « web scraping » est perçu différemment selon les juridictions, et les règles qui le régissent peuvent varier considérablement. Le « web scraping » est généralement considéré comme légal, bien qu’il puisse être illégal s’il enfreint les conditions de service, les droits d’auteur ou s’il permet un accès non autorisé à des données spécifiques.
Certains sites d’actualités et d’articles refusent explicitement le web scraping dans leurs conditions d’utilisation. Dans ce cas, le non-respect de ces conditions peut avoir des conséquences juridiques. En revanche, si les informations sont accessibles au public et que le scraping n’enfreint aucune condition, il est généralement considéré comme étant dans les limites de la légalité. N’oubliez pas qu’il est toujours essentiel de respecter les normes en matière de protection de la vie privée et d’obtenir le consentement des personnes concernées, le cas échéant, lors de la collecte d’informations sur le web.
Comment récupérer des sites web d’actualités et d’articles sans codage ?
Ne vous inquiétez pas si votre expertise technique ou votre connaissance de la programmation Python n’est pas de premier ordre. Octoparse est là pour faciliter vos besoins en matière de web scraping. Doté d’un riche éventail de milliers de fonctionnalités, il peut faciliter le scraping de nouvelles depuis presque n’importe quel site rapidement, même sans avoir besoin de Python ou de compétences techniques.
Octoparse est disponible en version gratuite et en version premium, offrant de nombreuses fonctionnalités complètes. Il est capable d’extraire plusieurs sites d’information rapidement. Mais comment l’utiliser exactement pour le scraping de sites web ?
Etape 1 : Entrer l’url du site de nouvelles et d’articles
Il suffit de copier et de coller l’URL souhaité dans la barre de recherche d’Octoparse. Cliquez sur le bouton « Démarrer », une nouvelle tâche sera initiée et la page web correspondante se chargera dans le navigateur intégré d’Octoparse.
Étape 2 : Créer un flux de travail et sélectionner les champs de données souhaités
Attendez que la page ait fini de se charger, puis cliquez sur « Autodétection des données de la page web » dans le panneau de conseil. Octoparse va scanner la page et mettre en évidence les données extractibles pour vous. Vous pouvez éditer les champs de données détectés et supprimer les champs inutiles en bas de page. Cliquez sur « Créer un flux de travail » une fois que vous avez sélectionné toutes les données souhaitées. Le flux de travail s’affichera sur le côté droit.
Étape 3 : Exécuter la tâche et exporter les données
Une fois que vous avez examiné tous les détails, vous pouvez continuer en cliquant sur le bouton « Exécuter ». Vous avez alors la possibilité d’exécuter la tâche sur votre propre appareil ou d’utiliser les serveurs cloud d’Octoparse. Une fois le processus entièrement terminé, vous pouvez exporter les données collectées vers des fichiers locaux tels qu’Excel ou une base de données comme Google Sheets pour une utilisation ultérieure.
D’ailleurs, il est toujours utile de vérifier d’abord s’il existe un modèle préétabli qui vous convient, avec lequel vous n’aurez qu’à remplir quelques paramètres pour récupérer les données dont vous avez besoin. Si aucun des modèles ne correspond à vos besoins et que vous ne souhaitez pas créer votre propre scraper, envoyez-nous par courriel les détails de votre projet et vos exigences. Nous sommes là pour vous aider !
Voilà une énumération des modèles qu’on propose sur la collecte des sites d’actualités et d’articles.
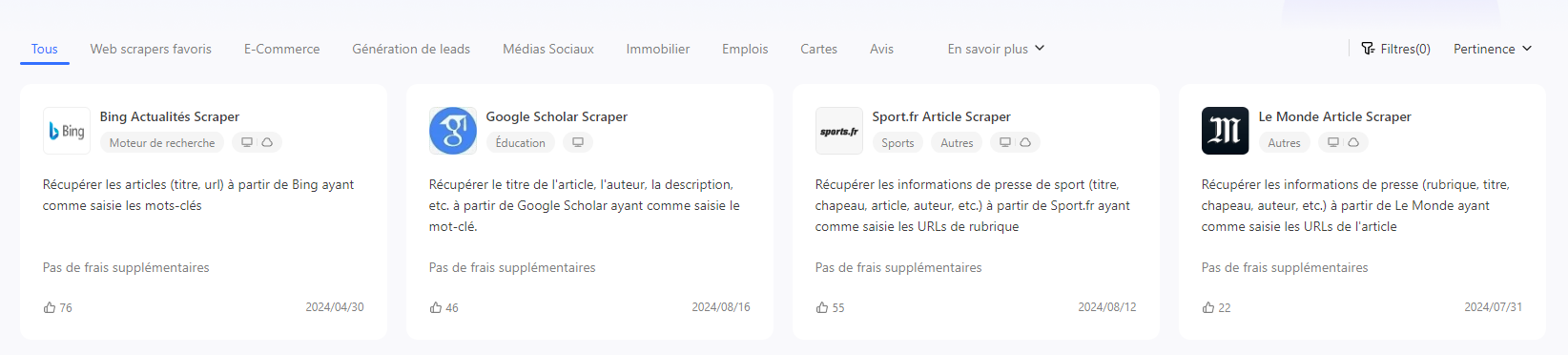
En outre, je voudrais vous introduire un scraper intéressant qui peut extraire les métadonnées et l’article intégral. Il vous suffit de saisir l’url dont vous souhaitez extraire les articles et saisir quelques paramètres pour commencer. Et ce modèle va extraire l’url de l’article, le titre, l’auteur, la date, les mots-clé, la description, le texte intégral et l’url des images s’il y en a.
https://www.octoparse.com/template/smart-article-scraper
Voilà ce que j’entre :
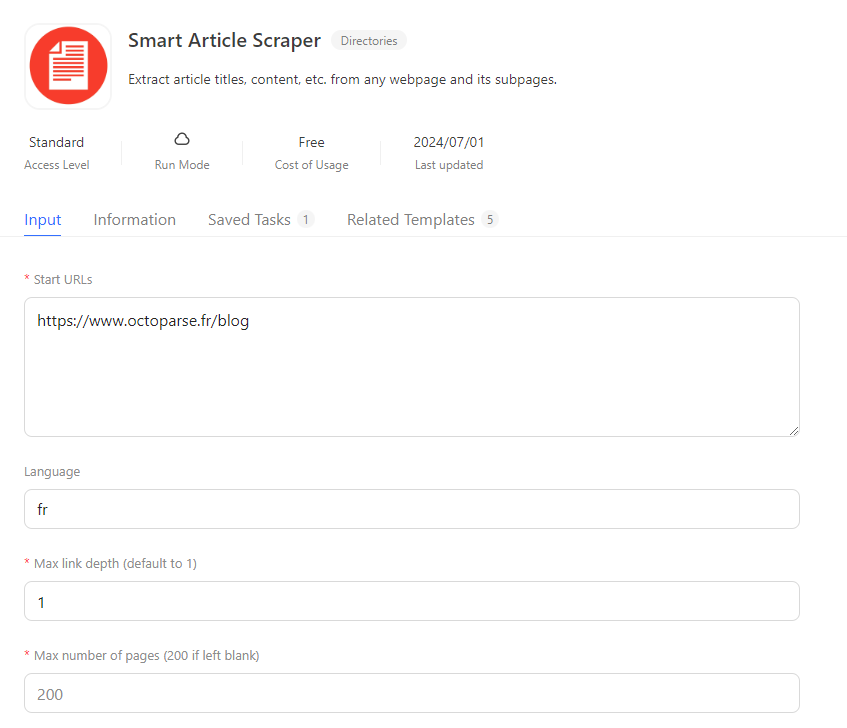
Et voilà ce que j’ai obtenu après avoir cliqué sur Essayez-le en haut à droite :
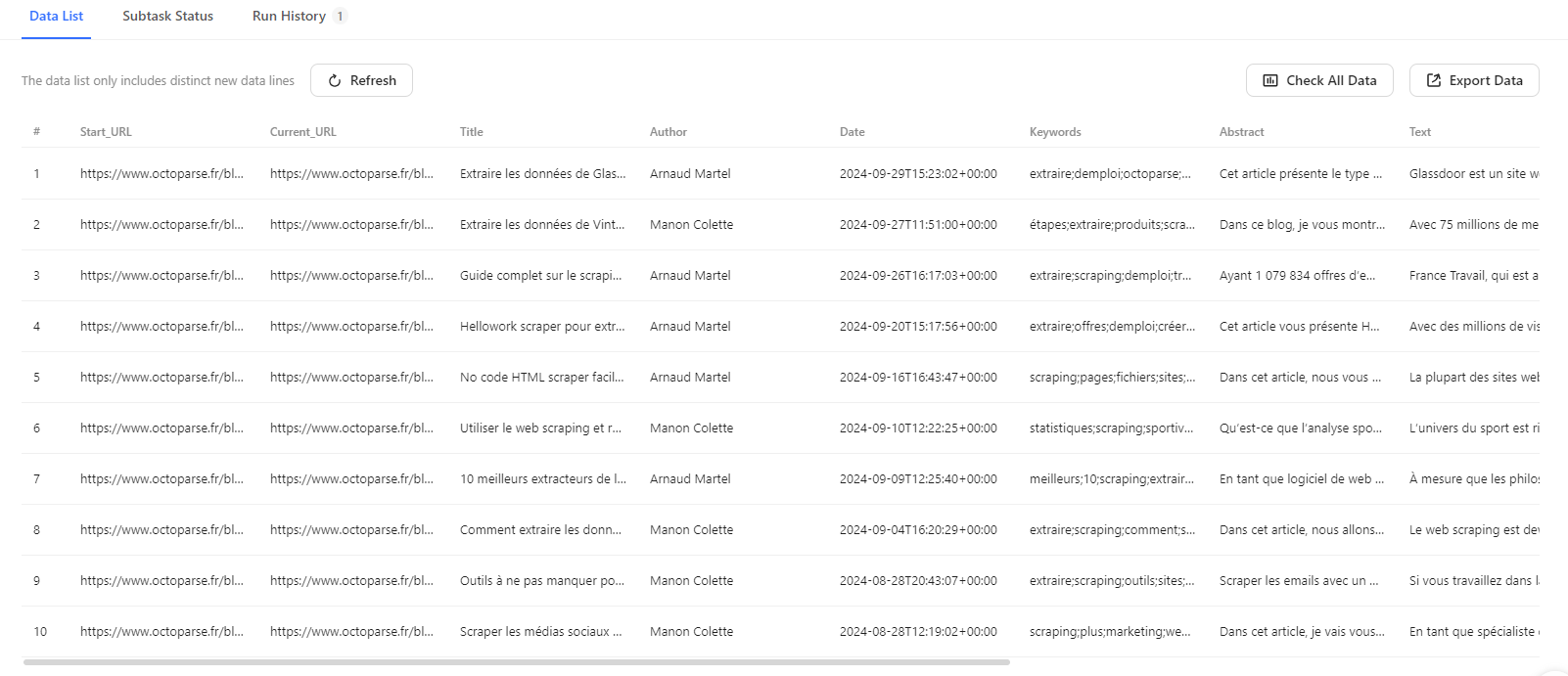
N’hésitez pas à essayer le modèle en saisissant l’url des articles qui vous intéressent pour obtenir toutes les données en un coup.
En conclusion
Le scraping est une méthode efficace pour agréger des informations importantes sur les grands titres mondiaux sans faire de recherches intensives. Octoparse est un excellent outil qui facilite l’extraction rapide de données à partir de sites web d’actualités et aide à collecter des informations et des données d’articles utiles pour stimuler l’activité. Alors, pourquoi attendre ? Téléchargez simplement le logiciel Octoparse et commencez votre voyage de scraping d’articles et de sites web d’actualités en toute transparence !

Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites Web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP et à l’API avancée.
Service Cloud pour programmer le scraping de données.