Enregistrer une image à partir de la page Web est simple. Il suffit de cliquer à droite et de sélectionner “Enregistrer l’image sous”. Mais que faire si vous avez des centaines, voire des milliers d’images à enregistrer ? Cette méthode fonctionnera-t-elle ? En tout cas, pas pour moi ! Voyons comment le scraper d’images peut vous aider.
Dans cet article, je vais vous montrer comment construire rapidement et facilement un scraper d’images sans aucune codage. Même si vous n’avez absolument aucune connaissance technique, vous devriez être en mesure de le faire en 30 minutes.
Nous allons donner quelques exemples que vous pouvez rencontrer tout en fournissant des étapes très détaillées.
Vous êtes prêt ? On commence !
Préparations
Avant tout, il faut que vous téléchargiez Octoparse sur votre ordinateur. C’est un logiciel puissant et totalment gratuit qui vous permet non seulement de scraper les images mais aussi tous autres genres de contenu affiché sur les pages Web. Et grâce à sa nouvelle version, vous pouvez même télécharger directement les images sur votre ordinateur local lors de l’extraction de données.
Si vous êtes tout nouveau sur Octoparse ou les outils de web scraping, il est préférable de consulter cette page de produit pour avoir une première idée sur les fonctionnalités et les applications étendues de ce logiciel.
Vous pouvez également regarder le vidéo suivant – un tutoriel qui donne un guide étape par étape pour apprendre aux utilisateurs à récupérer et à télécharger les images d’Aliexpress avec Octoparse. Tant que vous avez maîtrisé l’utilisation de cet outil, vous serez en mesure de scraper les images ou autre contenu sur presque tous les sites Web sans effort !
Comment créer un web scraper d’images sans coder ?
Dans cette démonstration, nous allons récupérer des images de chiens sur Pixabay.com. Après avoit fait une recherche de “dogs” sur Pixabay.com, vous devriez arriver à cette page.
Étape 1 : Entrer l’URL
Entrer l’URL dans la barre de recheche dans Octoparse pour lancer une nouvelle tâche en mode avancé avant de cliquer sur “Start”.
Étape 2 : Sélectionner les images que vous souhaitez enregistrer pour indiquer au robot les images à récupérer
Cliquer sur la première image. Le panneau de Tips indique maintenant “Image selected and 100 similar images found”. C’est génial, c’est exactement ce dont nous avons besoin. Sélectionner “Select all”, puis “Extract URLs of the selected images” ou “Extract image URLs and download linked files” si vous souhaitez les télécharger directement avec Octoaprse.
Étape 3 : Parcourir les pages pour extraire plus d’images
C’est sans aucun doute que nous ne voulons pas seulement les images de la page 1, mais celles de toutes les pages. Pour ce faire, il faut configurer la pagination.
Aller jusqu’au bas de la page actuelle et cliquer le bouton “next page”. Nous voulons évidemment cliquer plusieurs fois sur le bouton “next page”, il est donc logique de sélectionner “Loop click single URL” dans le panneau de Tips.
Étape 4 : Paramétrer l’auto-scrolling
Il y a une dernière chose à ajuster avant de lancer la tâche.
En effet, si vous lancez la tâche maintenant, vous trouverez qu’il y a des données redondantes dans le résultats.
Pendant le débogage, j’ai remarqué que le code source HTML change dynamiquement lorsque l’on fait défiler la page Web. En d’autres termes, si la page Web ne se défile pas pendant le scraping, nous ne pourrons pas obtenir les URLs corrects des images. Heureusement, Octoparse peut le faire facilement.
Nous devrons ajouter l’auto-scrolling au chargement de contenu. Il suffit de cliquer sur “Go to Webpage” dans le workflow et puis cocher “Scroll down the page after it is loaded”. Maintenant, il est à décider les détails de l’auto-scrolling. Les paramètres dans la capture suivante veut dire que le robot va faire scroller un écran de contenu à l’interval de 1 seconde pour 40 fois.
Ces chiffres ne sont pas fixés à ma guise, et bien au contraire, il s’agit de résultats de plusieurs ajustements et tests.
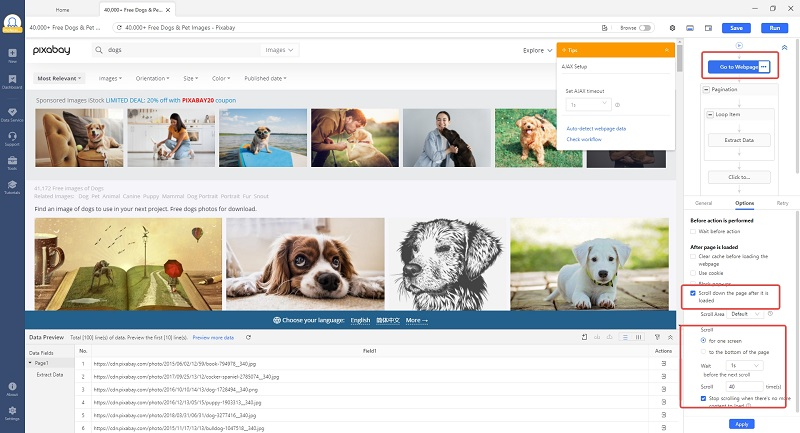
A l’étape de la pagination, il faut ajouter le même auto-scrolling. Cliquer sur “Click to paginate ” dans le workflow, utiliser exactement les même paramètres pour le défilement automatique.
Étape 5 : Lancer votre crawler !
Voilà, c’est fait. C’est terminé ! Lançons le scraper et voyons s’il fonctionne ou pas.
Ces cinq étapes sont déjà capables de scraper la majorité des sites web d’images. Si vous rencontrez des questions pour créer un scraper d’images, n’hésitez pas à nous contacter.
D’une façon générale, les images sont présentées sur les sites Web sous deux formes : les images miniatures ou les vignettes, les images en taille réelle. Les images miniatures, qui sont souvent des petites images compresssées, contiennent en effet un hyperlien vers les images en taille réelle correspondantes. Grâce aux images miniatures, une page Web peut afficher plus d’images ou de graphiques et également charger le contenu plus rapidement. Sa petite taille et la vitesse de chargement le fait le meilleur choix adapté pour une navigation rapide des images. On peut dire que c’est une table de matières de fichier d’images.
Exemple 1 : Récupérer des images en taille réelle [full-sized]
Pour cet exemple, nous utiliserons le même site web https://pixabay.com/images/search/dogs/ pour montrer comment vous pouvez obtenir les photos en taille réelle.
Étape 1 : Commencer une nouvelle tâche
Lancer une nouvelle tâche en cliquant sur ” + Task ” dans le mode avancé et entrer l’URL.
Étape 2 : Sélectionner les images que vous souhaitez télécharger.
Pour récupérer les images en taille réelle, nous devrons cliquer sur chaque image miniature afin de voir/obtenir l’image en taille réelle.
Cliquer sur la première image, le panneau de Tips doit indiquer “Image selected, 100 similar images found”. Et puis cliquer “Select all”.
Ensuite, “Loop click each image”.
Étape 3 : Obtenir les URLs des images
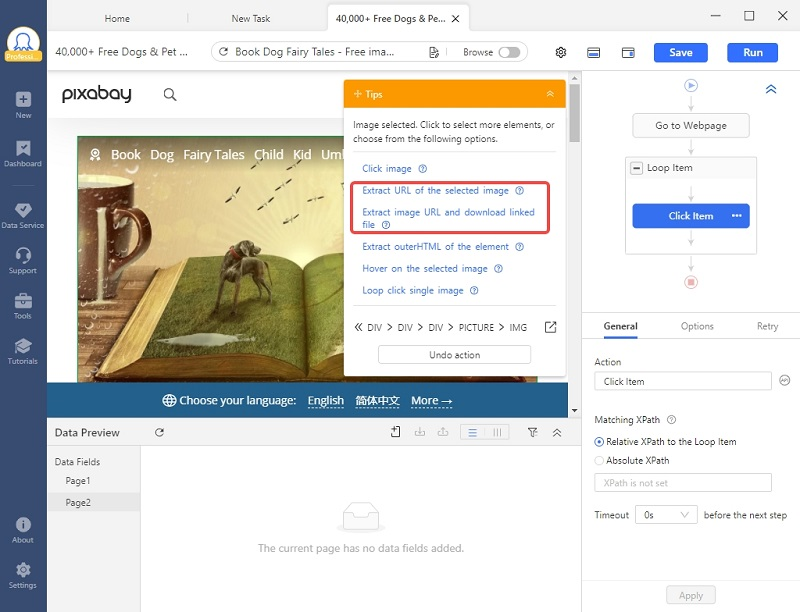
Maintenant que nous sommes arrivés sur la page de l’image en taille réelle, les choses sont beaucoup plus faciles.
Cliquer sur l’image en taille réelle, puis sélectionner “Extract URL of the selected image”.
Attention
Octoparse supporte le téléchargement de fichiers, permettant aux utilisateurs de télécharger directement les images en taille réelle lors de l’extraction de données.
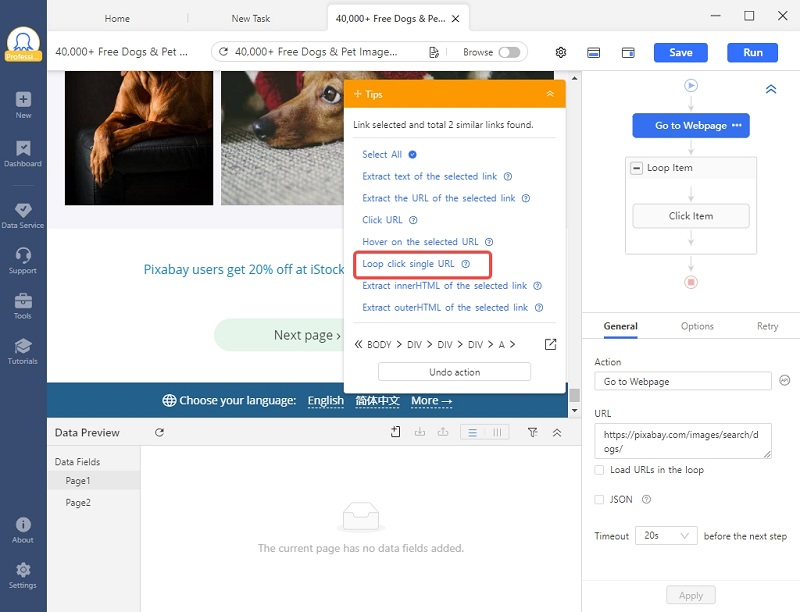
Étape 4 : Ajouter la pagination pour parcourir les pages.
Cliquer sur “Go to the webpage”, choisir le bouton “Next page” puis cliquer. Sélectionner “Loop click single URL” dans le panneau de Tips.
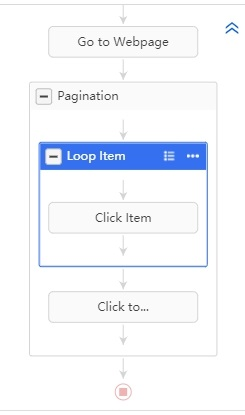
Le workflow devrait ressembler à ceci. Si ce n’est pas le cas, faites des glisser-déposer.
Étape 5 : Exécuter votre crawler !
C’est fait ! Tester le scraper.
Exemple 2 : Récupérer les images en taille réelle à partir des images miniatures
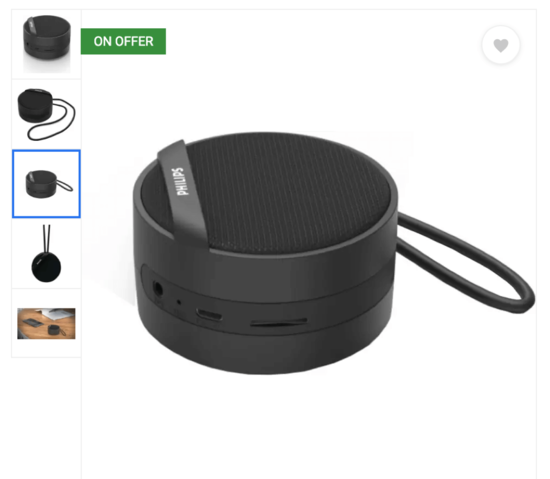
Il y a deux façons d’extraire les images en taille réelle à partir des images miniatures en utilisant Octoparse.
Option 1 – Vous pouvez configurer un clic en boucle pour cliquer sur chacune des images miniatures, puis procéder à l’extraction de l’image en taille réelle une fois celle-ci chargée.
Option 2 – Comme la plupart des images miniatures partagent exactement le même modèle d’URL que les images en taille réelle, mais avec des chiffres différents indiquant la taille, il est logique d’extraire l’URL des images miniatures puis de remplacer les chiffres de taille de la miniature par ceux de l’image en taille réelle. Voyons comment Octoparse le faire facilement !
Pour faire une démonstration, nous allons utiliser une page de produit sur Flipcart.com.
L’URL d’exemple est
Avant de commencer le travail, il est nécessaire de confirmer si cette tactique peut être appliquée. Donc, il faut vérifier les URLs de l’image miniature et celle en taille réelle.
Par exemple :
| URL de l’image miniature : https://rukminim1.flixcart.com/image/128/128/jatym4w0/speaker/mobile-tablet-speaker/v/u/7/philips-in-bt40bk-94-original-imafybc9ysphpzhv.jpeg?q=70URL de l’image en taille réelle : https://rukminim1.flixcart.com/image/416/416/jatym4w0/speaker/mobile-tablet-speaker/v/u/7/philips-in-bt40bk-94-original-imafybc9rqhdna8z.jpeg?q=70 |
Il n’est pas difficile à remarquer que la seule différence entre ces deux URLs est les chiffres indiquant la taille de l’image. “128” pour la miniature et “416” pour l’image en taille réelle.
Donc, pour récupérer les images en taille réelle à partir des images miniatures. Notre stratégie : 1. extraire les URLs des miniatures ; 2. remplacer simplement “128” par “416”.
Étape 1 : Entrer l’URL
Lancer Octoparse, commencer une nouvelle tâche, puis saisir l’URL cible dans la zone de texte.
Étape 2 : Sélectionner l’image miniature
Cliquer sur la première image miniature. Le panneau de Tips à droite indique maintenant “Image selected and 6 similar images found.”. Bravo ! Octoparse a reconnu automatiquement les autres miniatures.
Sélectionner “Select all”.
Ensuite, sélectionner “Extract URLs of the selected images “. Ce n’est évidemment pas ce que nous voulons, mais nous pourrons le modifier plus tard.
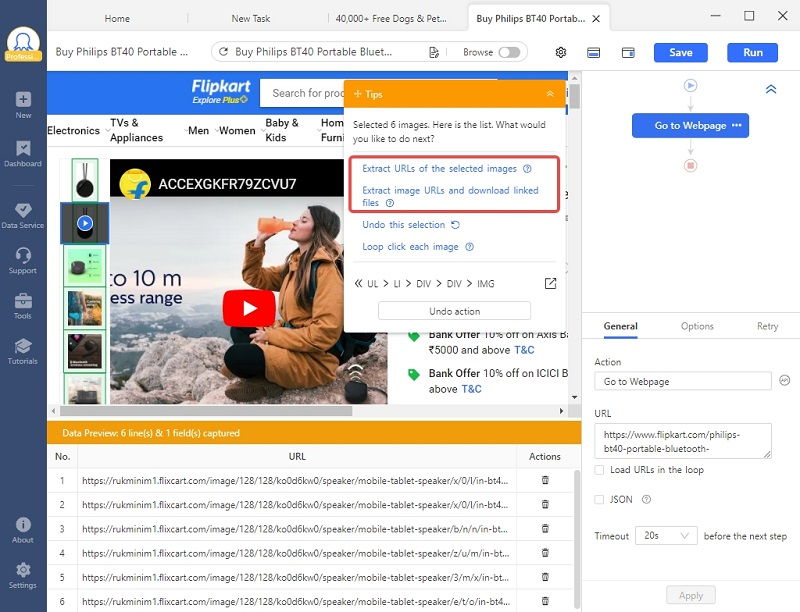
Étape 3 : Nettoyer les données pour modifier les URLs
Dans le panneau de “Data preview”, cliquer les trois petits points au haut à droite. Choisir “Clean Data” — “Add step” — “Replace”, Remplacer “128” par “416”. Cliquer sur “Evaluate”. Et voilà, nous avons l’URL dont nous avons besoin.
L’outil RegEx est également souvent utilisé pour nettoyer les données. Par exemple, si on a à la main le code HTML, on peut mettre en service l’Expression régulière pour obtenir les URLs.
Étape 4 : Lancer le scraper
Maintenant, nous avons extrait avec succès les URLs des images en taille réelle. En effet, vous pouvez totalement directement télécharger les images avec Octoparse. Ou vous pouvez aussi exporter les résultats dans un Excel local avant de les mettre dans des téléchargeurs d’image, TabSave, par exemple. Il existe également d’autres téléchargeurs d’images similaires disponibles sur le Web et la plupart sont gratuits.
J’espère que ce tutoriel vous donnera un bon départ dans l’extraction d’images/données du Web. Faites un essai ! Cela dit, chaque site Web est différent et il faut parfois des ajustements pour que cela fonctionne.
Si vous avez des questions sur la configuration d’un crawler dans Octoparse, vous pouvez consulter Octoparse Help Center ou nous contacter directement.




